Training a Custom Multimodal Models for Enhanced Energy RAG Solutions
Introduction
Large multimodal models are a critical part of advanced artificial intelligence (AI) systems that can process and integrate text, images, audio, and video using deep-learning methods. These models excel at interpreting complex information, offering more accurate and context-aware responses. Their versatility supports a wide array of applications, from improving virtual assistants to advancing autonomous systems, pushing the limits of machine capabilities and artificial intelligence.
Traditional AI models like large language models (LLMs) and vision models (e.g., SAM) focus on text and images separately. In contrast, multimodal models such as LLaVA, GPT-4V, and Gemini combine both text and images, allowing for responses that blend textual and visual elements seamlessly.
The energy related documentation has domain specific knowledge, and content encompassing both textual and visual components. To effectively process these files and carefully handle the semantic complexities, it is important to leverage the interaction between their textual and visual content for a complete understanding. In this blog, we highlight the capabilities of multimodal models and discuss the fine-tuning process on energy-related datasets to develop a multimodal retrieval-augmented generation (RAG) solution.
Steps in Building a Multimodal RAG Solution on Energy Documents
We are building a multimodal RAG system that takes as input an image from a domain specific document along with a user query/question related to the image itself or larger document context.
Creating a system that processes an input image and question to extract information from a database involves multiple stages. These stages range from fine-tuning a vision-text encoder, such as LLaVA, to deploying a multimodal RAG solution on our document collection. The detailed steps of this process are outlined in the following sections.
Preliminary - LLaVA Architecture
The architecture of LLaVA model involves a sophisticated mechanism for integrating the visual features extracted by the CLIP ViT-L/14 with the textual processing capabilities of LLM. This architecture typically involves a feature fusion module that combines visual and textual embeddings, allowing the model to understand context and perform tasks that require both visual and textual understanding. The visual encoder, CLIP ViT-L/14, excels at extracting features from images. The language backbone of LLaVA 1.6 is based on LLaMA-2 which is an enhanced version of the original LLaMA model.
In contrast to proprietary models like GPT-4 Vision by OpenAI and Gemini by Google, LLaVA emerges as a prominent open-source alternative. LLaVA’s cost-effectiveness, scalability, and notable performance in multimodal benchmarks, especially LLaVA 1.6, make it an enticing choice for a variety of multimodal tasks, such as visual question answering, image captioning, and visual reasoning.
Step 1—Dataset Generation
Fine-tuning multimodal models on domain specific data allows the model to adapt to specific tasks, domains, or user requirements; thereby, increasing its relevance and effectiveness in those areas. Generating visual question answering (VQA) pairs to fine-tune LLaVA is an essential step to tune the model to achieve the desired model performance.
There are several methods to create a training dataset, such as manually deciphering answers based on input image-question pairs or using large multimodal models like GPT-4V and Gemini to generate answers from provided image-question pairs.
Although manually deciphering answers for each question can ensure accuracy, it is a labor-intensive process. Employing GPT-4V to generate answers allows for streamlining the process. One can then validate and correct these answers with the help of domain experts, ensuring both efficiency and accuracy in creating a high-quality dataset for fine-tuning the LLaVA model.

Figure 1—Dataset generation method for most of the multimodal model fine-tuning.
The workflow of a common method to generate VQA pairs for fine-tuning LLaVA is shown in Figure 1.
Step 2—Model Fine-tuning
As shown in Figure 2, the LLaVA model consists of three sections: vision encoder, projector, and language model. Specifically, the projector is for aligning visual embeddings into word embedding space. Both the vision encoder and the language model of the LLaVA model are pretrained on large datasets. The vision encoder is pretrained using contrastive learning on image-text pairs, while the language model is pretrained on a vast corpus of text data to understand and generate human-like language.
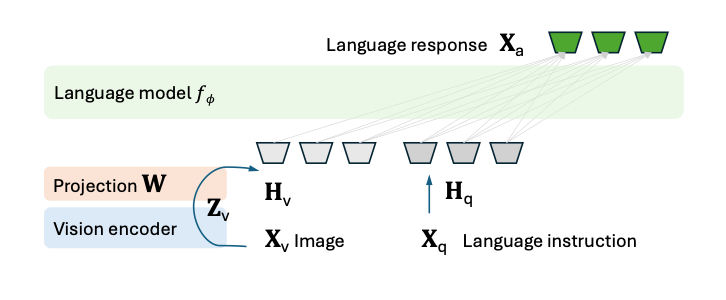
Figure 2—LLaVA model architecture.
In the pretraining stage for feature alignment, keeping both the vision encoder and the language model frozen, general VQA datasets are used to update the parameter of the projector. This approach aligns the image features Hv with the pretrained word embeddings of the LLM. Essentially, this phase can be treated as training a visual token, which is compatible with the frozen LLM.
After pretraining, LLaVA 1.6 can be fine-tuned on specific datasets that are designed to enhance its performance on tasks requiring the integration of visual and textual information. This fine-tuning process ensures that the model can adhere to instructions accurately and perform complex tasks involving both modalities.
For the fine-tuning process, use the domain-specific image dataset and the generated VQA pairs to update the parameters of the projector and language model, while keeping the vision encoder frozen. The same generative loss is used in this stage, and the answer generated by GPT-4V is regarded as the ground truth answer for each data point.
Step 3—Extraction and Generation for Energy Custom Data
When investigating the latest fine-tuning techniques and multimodal retrieval approaches in the literature, only recent studies present these subjects, e.g., Wiki-LLaVA from the IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR) 2024.
Based on state-of-the-art methodologies, the proposed workflow shown in Figure 3 is used to retrieve relevant information from the context given a query and an input image. For that purpose, in the first step, we conduct an approximate k-nearest neighbor search on the document titles to locate the most pertinent documents. The similarity between the query image and the text titles is computed using the visual and textual encoders.
In the second step, the retrieved documents are analyzed to identify the most relevant passages corresponding to the user's question. Then, a visual-language model like BLIP is used to retrieve the most appropriate passages.
Finally, the fine-tuned LLaVA model is used to generate a coherent answer to the query based on the retrieved context and input image embeddings.
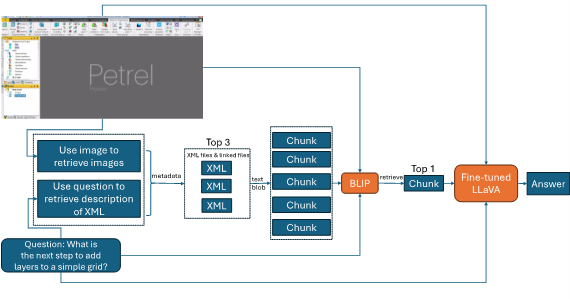
Figure 3—Incorporate the custom fine-tuning process tailored to the service company’s internal data.
Results
Our preliminary findings indicate that on the same dataset, LLaVA-1.6, achieves better metrics, indicating that improving the model itself can enhance the task performance. In addition, improvements were made from the dataset perspective. To deeply explore image features, the categorical VQA dataset with unique questions was tailored to different types of images, helping the model better understand image data in this domain.
The trained model's performance was evaluated by answering questions based on domain images and queries from the software documentation. The questions were related to both the image and context, and the model effectively retrieved relevant chunks and integrated knowledge from both the image and the text.
Figure 4 shows an example of the resulting VQA based on context.
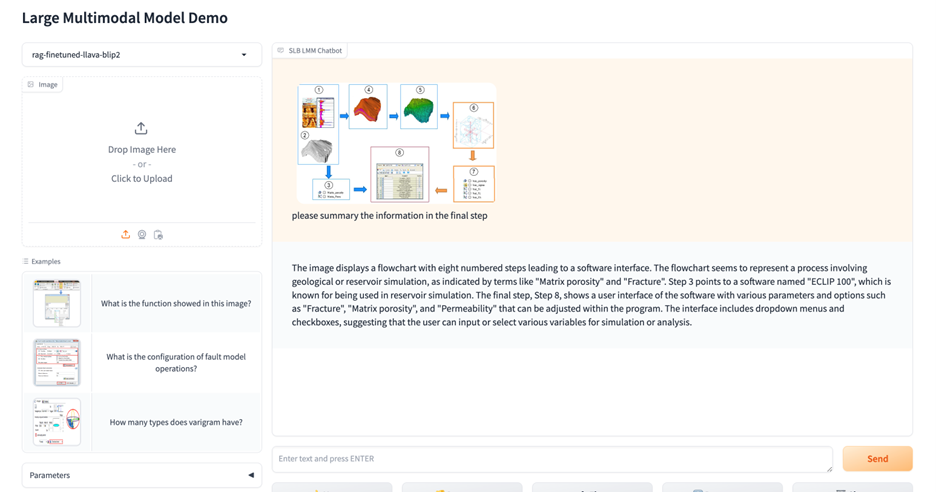
Figure. 4—RAG example result.
Conclusions
The integration of vision-text encoders and multimodal models with domain-specific data shows promising preliminary results. Fine-tuning models like LLaVA on energy domain datasets has initially improved accuracy and relevance of the output. This preliminary work indicates strong potential in combining image and text for complex queries, with early findings suggesting that fine-tuned models like LLaVA-1.6 could outperform baseline models. This advancement allows for creating more comprehensive solutions that leverage the company’s expertise, knowledge, documentation, and domain-specific resources.