Empowering Drilling and Optimization with Generative AI
A novel solution to this problem is proposed—a framework that, to the best of our knowledge, represents the first application of Text-to-SQL using LLMs within the Oil & Gas (O&G) domain, specifically designed to handle complex database structures. This paper presents a novel solution that bridges the gap between drilling engineers' need for efficient data access and their lack of specialized data skills. Our Natural Language (NL) to SQL GenAI workflow transforms complex data transformation operations into a seamless process requiring no special expertise and delivering results within seconds. By converting natural language queries into SQL queries, this framework dynamically enriches users' questions with relevant contextual information before processing them through a Large Language Model (LLM). This ensures that drilling engineers can quickly analyze multi-well data, address critical issues, and capture knowledge for future wells, all while overcoming the challenges of accessing and interpreting large SQL databases.
Keyword: Text-to-SQL, LLMs, Prompt engineering
Introduction
As the world goals move towards a more sustainable future every project in O&G gets scrutinized to maximize value of operations. Drilling Engineers are on the spot to leverage all data available to optimize design and operations. O&G companies have been effectively collecting data over the last few decades and have effectively stored large amounts of high frequency sensor data as well as reporting data. Efficient data access is becoming fundamental for O&G upstream projects and data operations skills critical for Drilling Engineers in charge of the wells. While Petroleum Engineering and Drilling Engineering programs have started to include data and data science courses in their syllabus data operations, it is still far from becoming a core competency for most of the Drilling Engineering community.
This paper introduces the solution implemented is closing this gap between Drilling Engineers needs for access to data and their skills and time available to access to data. The solution is a GenAI-powered Natural Language (NL) to SQL pipeline that transforms lengthy data transformation operations, sometimes out of the skill level of Drilling Engineers, in a process that takes seconds and requires no technical skills to operate, therefore empowering access to data to non-data professionals.
Statement of Theory and Definitions
Theory
GenAI: Generative AI (GenAI) refers to a class of artificial intelligence (AI) algorithms that can generate new content based on the data algorithms have been trained on. In the context of drilling and optimization in the O&G industry, generative AI can be used to synthesize new drilling strategies, optimize existing processes, and predict potential findings based on historical data.
Text-to-SQL: Text-to-SQL application is a specific technique that converts natural language processing (NLP) into SQL queries that can be executed on databases. This conversion from natural language (NL) to code is done thanks to AI models specifically trained to convert NL queries into structured query language (SQL) statements and it implies that large language models (LLM) should understand the schema used in the data model.
This application allows industries to interact with complex databases using everyday language, thus improving accessibility and efficiency in data retrieval and analysis. The use of generative AI and Text-to-SQL in O&G operations is revolutionizing the way drilling data is consumed and analyzed, opening doors for industries that want to leverage these technologies to improve decision-making on real-time data, reduce operational risks, and enhance overall productivity.
Definitions
- Natural Language Processing (NLP): A field of AI focused on the interaction between computers and humans through natural language. It involves enabling computers to understand, interpret, and respond to human language in a valuable way.
- Large Language Model (LLM): A large language model (LLM) is a type of artificial intelligence (AI) program that can recognize and generate text, among other tasks. LLMs are trained on huge sets of data — hence the name "large." LLMs are built on machine learning: specifically, a type of neural network called a transformer model.
- Drilling Optimization: The process of improving drilling efficiency and effectiveness through various means such as advanced data analytics, AI algorithms, and real-time monitoring. Optimization aims to minimize costs and maximize resource extraction while ensuring safety and environmental standards.
Description and Application of Equipment and Processes
Challenges
- Lack of prior works: Despite significant advancements in Text-to-SQL research, most existing benchmarks, such as WikiSQL [1], Spider [2], and Bird [3], are primarily focused on general knowledge domains and lack specialization in the Oil & Gas (O&G) sector. This gap presents a challenge, as there are currently no established benchmarks to the complexities of O&G data, making it difficult to initiate the fine-tuning process or conduct accurate evaluations of models in this domain. Moreover, our research identified that related work in this area is not only outdated but also limited in scope; previous approaches often involved overly simplistic SQL queries and relied on models like T5 [4].
- Data quantity: Having a sufficient number of Question-SQL pairs is crucial for ensuring high-quality results from a Gen-AI solution. However, crafting just one SQL query from a natural language question can be a time-consuming process, sometimes taking up to two weeks or even more. To address this challenge, data augmentation techniques using large language models (LLMs) were employed. These models helped to expand the dataset of Question-SQL pairs, which not only supports more effective few-shot learning but also aids in ongoing solution monitoring over time.
- Model interpretability: a significant challenge when deploying LLMs is making them explainable for the end users. LLMs, often seen as “black boxes”, lacks transparency in the outputs they generate and therefore would undermine user confidence, especially when using it for critical decision making.
- Accuracy measurement: As the proposed solution is used by drilling engineers for taking critical business decisions, another challenge was to be able to monitor the solution performance to ensure the accuracy is not decreasing over time. This involves performing cost versus accuracy analysis and developing tailored metrics for text-to-sql applications.
- Translation to SQL: Translating natural language queries into SQL is particularly challenging when dealing with complex database structures and domain-specific logic. For instance, consider the query:
Retrieve the names of all wells that have produced more than 10,000 barrels per day in July 2023, and calculate the total production for each of these wells across all reservoirs they are connected to.
Generating an accurate SQL statement for such a query requires multiple joins, handling nested conditions, and applying domain-specific knowledge. The resulting SQL might look like:
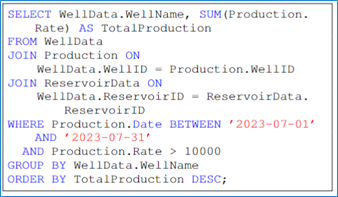
Fig. 1— Example of a complex SQL query output expected from the solution.
This query involves complex joins between multiple tables, filtering based on specific conditions, and aggregating results. All of which require a deep understanding of both the database schema and the domain-specific context. By addressing these challenges, the proposed solution can significantly enhance drilling and optimization processes in the oil and gas industry.
Proposed solution
The following solutions aim to overcome the complexities in Text-to-SQL generation for drilling optimization described in the challenge section above.
- Data Model definition: Defining the right table schema is critical for the LLM to understand the data it can use to generate SQL queries. The table schema defined involves:
- The table name and description
- The column name, description and type
- Foreign keys to explain how tables are related to each other
- Enumeration of non-numerical values to avoid hallucinations on categorical values (ex: well name, BHA name, direction type….)
- - Harnessing Hallucinations thanks to the data model definition:LLMs can easily make up new information and, in this specific text-to-SQL task, it is expected to hallucinate on column names, table names or even jointures keys between tables.

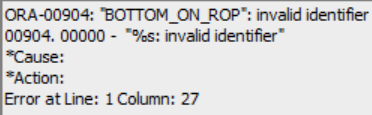
Fig. 2— Example of hallucination on the column name leading to an execution error. (a) Question from a user (drilling expert). (b) SQL statement corresponding to the question above the figure. (c) Resulting Oracle SQL error.
At the value level, some examples of hallucinations can occur in case of misspelling of categorical variables from the user (for instance if the drilling engineer is asking for results to be filtered on specific well names, or operations codes. If the LLM is not fed with enumerations of values like ‘DRILL’ (corresponds to ‘drilling’ operation’), or ‘CEMENT’ (corresponding to ‘Cementing’ operation) is it assumed that the user must put the exact same codes as found in the databases. However, expecting the users to master each table information that comes with the million data points is unrealistic.
- In-context learning: By leveraging Retrieval Augmented Generation (RAG) method, the user prompt is enriched with drilling context (Key Performance Indicators (KPIs) definitions, table schema information)
- Building the enriched instruction prompt: The final prompt sent to the LLM consists of an instruction sentence, followed by the user question enriched with relevant context information and ends with dynamic few-shot learning, by passing relevant examples of question-SQL pairs as per the original user question to teach the LLM other similar examples.
- Self-correction LLMs loop: The SQL query goes through a quality check step to assess its syntactic accuracy. In case of syntax error or hallucination on the table and/or columns used, an additional LLM will correct the previously generated SQL.
- Accuracy measurement solution: As the solution is integrated in software systems, monitoring the performance with custom metrics was critical. Using tools like LLM-guard and accuracy metrics also helped fortify the security of the global solution and the model’s performance.
- Ensuring Model interpretability for the end-user: The solution that was thought of was to provide a natural language explanation of the resulted table shown to the user. This sentence provides the necessary information for the user to trust and understand the generated SQL and therefore the computation being done behind the scenes on the SQL databases. This information comprises:
- The table name(s) used in the SQL generated
- The column name(s) used
- The aggregation method(s) (i.e. average, max, min…) and jointure(s) used between tables
Datasets
A first dataset comprising 24 ground truth pairs of prompts and corresponding Oracle SQL queries – which was later augmented with +500 more pairs-, created by drilling engineers, was utilized for this study. These pairs were derived from a diverse set of 9 distinct tables with varying sizes and column structures, introducing significant complexity into the SQL query generation process. The development of these SQL queries was a collaborative effort involving two developers, who worked closely to translate the prompts into SQL. This process required multiple iterations with the Product Owner (PO) to refine the queries, resulting in a time-consuming and intricate workflow. The proposed methodology aims to eliminate the need for these iterative refinements, thereby streamlining the interaction between the client, PO, and developers. Additionally, the dataset incorporates 299 external knowledge entries, offering crucial domain-specific insights that were integrated into the query generation process, enhancing the contextual relevance and accuracy of the results.
Given the diversity and limited scope of the dataset, a uniform comparison of SQL queries proved challenging. Consequently, the queries were categorized into two levels of difficulty: "easy" and "hard." To achieve this classification, a version of the GPT-4o model (version 2024-05-13) [5] was employed, ensuring consistency and reproducibility. While human classification was initially considered, it was ultimately deemed too time-consuming for the finalized dataset. The model-based approach facilitated efficient processing and consistent classification across all queries. To account for the variability inherent in language models, each query was classified five times, with the most frequently occurring classification determining the final difficulty level.

Figure 3 Example of SQL table with drilling data containing summary of operations with public data.
The classification prompt used is as follows:

Data augmentation was performed using prompt engineering techniques, leveraging the same model version as in previous stages. This process expanded the dataset and significantly enhancing the original volume.
- Original set (Blue Bar) (~4.5% of the whole data): Consists of the initial 24 pairs.
- Extended set (Orange Bar): This category includes paraphrased prompts and SQL queries to diversify the semantic relationships within the data.
- Synthetic set (Blue Bar) (Blue and Orange Bars, combined ~95.5% i.e. 507 data points): These pairs were entirely generated based on the SQL table schema, creating additional data points. The synthetic and extended data set represent of our validation set.
This expanded and varied dataset supports a more comprehensive evaluation process. However, an imbalance in difficulty levels was noted, primarily due to the post-processing steps required to ensure accurate execution within the Oracle database and to eliminate duplication. The "hard" level questions, being more complex and semantically nuanced, are anticipated to present greater challenges compared to the "easy" level.
For subsequent experiments for both fine-tuning and evaluation, the Original set and 70% of the Extended set were designated as the test set, with the remaining data utilized for training. Including a portion of the Extended set in the training data was intended to increase the size of the test set, thereby enabling a broader quantitative evaluation and incorporating some "domain-specific knowledge" into the training process. Stratification was applied to maintain a balanced representation of difficulty levels across both easy and hard questions.
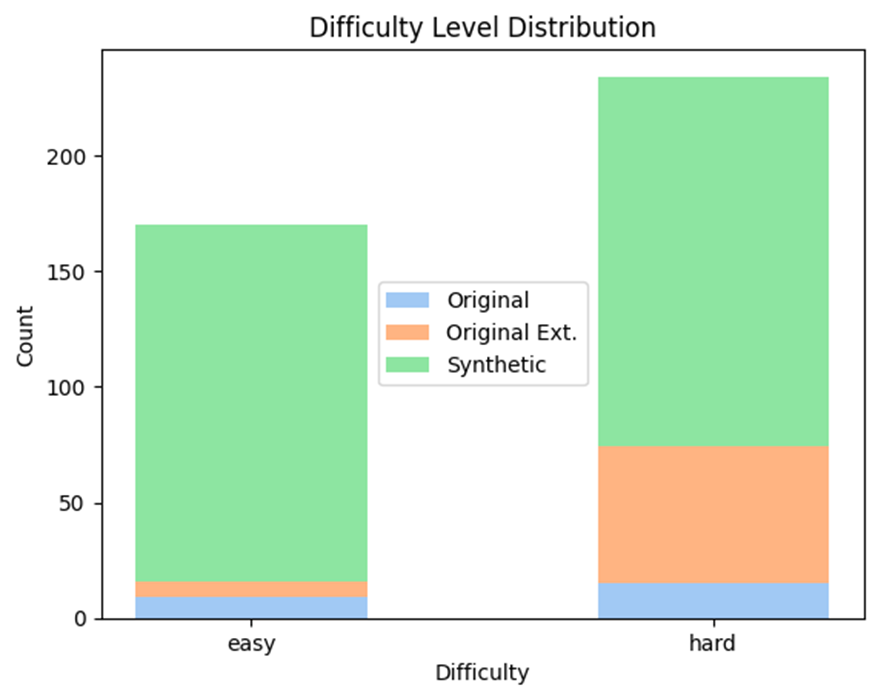
Figure 4: Histogram of validation set used for the pipeline containing easy and hard questions.
Methodology
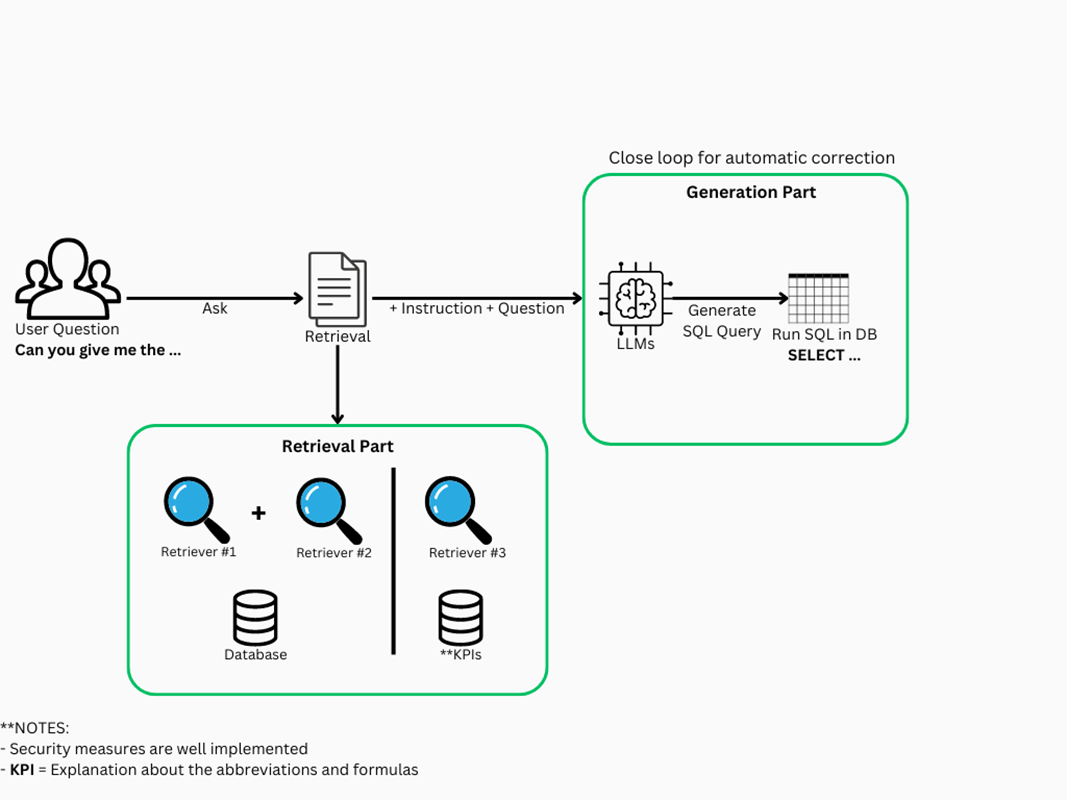
Figure 5: Diagram of the Text-to-SQL pipeline for drilling optimization.
As illustrated in the figure 5, the process begins when a user poses a question, such as “Can you give me the average on bottom ROP for the wells of the project?". This triggers the Retrieval phase of the pipeline, where relevant contextual documents are captured based on the user question. The process follows with the generation phase where the SQL query is created. This query enters then an automatic corrective loop that will solve the potential errors resulting from the execution of the SQL query against the table(s). Given the increasing complexity of the proposed pipeline, the problem was divided into two distinct components: the retrieval part and the generation part. This separation allows for more straightforward evaluation and easier scalability if needed. Each of these components will be discussed in detail in the following sections.
Retrieval Part
In the Retrieval Process, as previously discussed, two independent document retrieval systems are utilized: one for obtaining database-related information (such as tables) and another for accessing external knowledge. For the primary retrieval system, a blend of multiple retrieval techniques was selected to improve the effectiveness of the search.
- BM25: A sparse retrieval method that ranks documents by the occurrence of query terms within them. BM25 is effective at identifying relevant documents by focusing on exact keyword matches and adjusting for factors like term saturation and document length [6].
- Cosine Similarity: A dense retrieval method that measures the cosine of the angle between two vectors in a multi-dimensional space. This approach captures the similarity between vectors (representing documents and queries) based on their directional alignment, which is particularly useful for identifying semantic similarities beyond simple keyword matches [7].
The documents were converted into embeddings using OpenAI's Text Embedding Ada 2 [8] model and stored in the vector database Chroma. This combination of retrieval methods, often referred to as "hybrid search," [9] leverages the strengths of both sparse retrieval (e.g., BM25) for keyword-based matching and dense retrieval (e.g., Cosine Similarity) for capturing semantic relationships.
The table below shows the average accuracy of the hit rate for each retrieval method. The green bar represents retrieval using LLMs, the blue bar represents dense retrieval, and the pink bar represents sparse retrieval. The long context retrieval nor any LLMs were discarded from the analysis for cost and time efficiency constraints.
Generation part
Inference
In the Generation Process the model GPT4-turbo was used, once the relevant context from the Retrieval Process, the user's query, and predefined instructions are received, a large language model (LLM) is used to generate the corresponding SQL query. We don’t fine-tune open-sourced models because hosting a model with 70B parameters demands specialized hardware like dual A100 GPUs, which would cost approximately $2,000 per month in regions where such resources are available. A cloud-based hosted model is a more feasible and cost-effective option, providing scalability and reducing the need for significant upfront infrastructure investment. Additionally, to achieve results comparable to GPT-4, models with 7B, 13B, or 34B parameters wouldn’t be sufficient. To improve the accuracy of SQL generation, a detailed instruction of constraints was applied to guide the LLM in constructing the SQL query. Given the inherent variability in LLM outputs, there were instances where the generated SQL queries contained inaccuracies or syntax errors. To address these issues, an automated correction loop was implemented. This loop prompts the LLM to refine the SQL syntax based on identified errors, and typically, after a few iterations, a valid SQL query is produced, thereby optimizing the overall process. Once a correct SQL query is generated, it is executed on the database, and the resulting data is presented to the user in a tabular format for further analysis.
Auto-corrective LLM Loop
Due to the unpredictable behavior and outputs of LLMs, incorrect SQL syntax was sometimes generated. To resolve this issue, an automated correction loop was implemented. A prompt instruction was used, gathering the originally produced SQL along with the error and was then sent to the LLM. This self-corrective methodology now enables to get a correct SQL query after up to 2 iterations for most cases, therefore enhancing the overall robustness and performance of the product.
Evaluation
Retrieval Part
To assess the retrieval methods' effectiveness, Recall (True Positive Rate) was employed, measuring the model's accuracy in identifying the correct positives. The evaluation involved extracting table names from the generated SQL queries and comparing them to the actual tables to determine the correctness of the retrieval.
Recall = True Positive (TP)/True Positive (TP)+False Negative (FN)
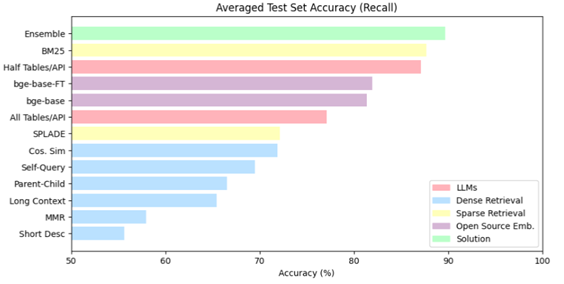
Fig. 6—Comparison of different retrieval techniques performance on the Questions-SQL pairs test set
The Figure 6 illustrates the performance of different retrieval strategies, including the application of LLMs, which, despite higher costs, ranked among the top three. Dense retrieval techniques, like cosine similarity, self-query, and those leveraging extended contexts, provided solid baselines but faced certain limitations in their effectiveness. Conversely, sparse retrieval methods demonstrated a balance between efficiency and effectiveness. A hybrid approach that combined sparse and dense retrieval techniques was explored, aiming for improved performance. This approach delivered on expectations, securing the leading position on the leaderboard with notable recall rates, particularly in challenging scenarios. Further enhancements, such as incorporating external knowledge sources, resulted in a modest but meaningful increase in recall scores, making this method the most suitable for the current task.
Generation Part
To assess the effectiveness of the Generation Part, we first gathered the relevant documents and tables for each prompt-SQL pair, enabling a focused evaluation of the generation component. Initially, we employed Execution Accuracy (EX) as described by Yu et al. (2018), emphasizing the accuracy of the retrieved data while allowing for variations in the generated SQL queries. This evaluation was carried out using an Oracle database, where the performance of the NL2SQL system was measured by comparing the execution results of the ground-truth SQL queries against those of the generated SQL queries. The EX-metric is defined as follows:
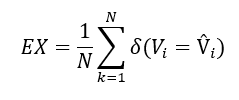
with N representing the total number of queries, and δ being a boolean function equals to 1 if the execution result set Vi matches the predicted set V̂i , and 0 otherwise. Given the limitations of the EX-metric, which proved inadequate in fully capturing the model's capabilities in our specific context, we refined our evaluation approach by incorporating a method inspired by Defog AI [10]. This enhanced evaluation, termed "Value Execution Evaluation" (VEX), goes beyond basic structural comparisons to assess the accuracy of the specific values retrieved, particularly in cases where variations in the `WHERE` clause could significantly impact the results.
Below is the formula to compute the VEX score:
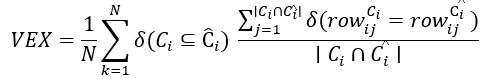
In this context, Ci and Ĉi represent the sets of columns in the ground-truth and generated result sets, respectively. The first part of the formula, represented by δ(C_i⊆C ̂_i ), checks if the generated columns are a subset of the ground-truth columns. The second component computes the ratio of matching values between the generated and ground-truth result sets within these columns. As noted above, this method allows for flexibility in accounting for differences that may arise from filter clauses. This approach allowed for a more comprehensive analysis of both the structure and the content of the generated SQL queries. The figure below illustrates the VEX accuracy across different models, with comparisons made between fine-tuned versions of GPT and Mistral models. Notably, the fine-tuned GPT-4 model (gpt4_ft) outperforms other models, especially on easier tasks, as indicated by the higher accuracy bars. This demonstrates the model's robustness in generating correct SQL queries when the retrieval is relatively straightforward. However, when the task complexity increases, as seen in harder queries, the performance gap narrows, indicating that even the fine-tuned GPT-4 struggles with more challenging retrievals. Interestingly, the gpt4ft-prod model, which integrates our retrieval solution, shows a slight drop in performance compared to the gpt4_ft model. This decline suggests that while the retrieval solution enhances the model's ability to retrieve relevant content, it may also introduce inconsistencies or omissions that affect the overall accuracy of the SQL generation. In contrast, the baseline GPT-4 and Mistral models exhibit more variability in their performance, particularly on hard tasks, further highlighting the importance of fine-tuning and robust retrieval mechanisms.
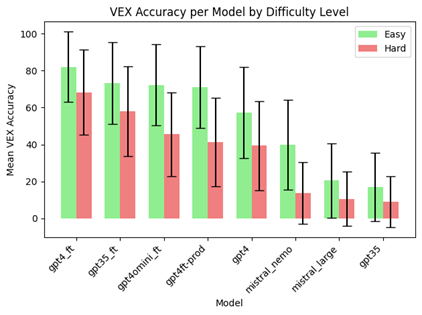
Fig. 7—Mean VEX accuracy score for vanilla and fine-tuned LLMS performed on the Questions-SQL pairs test set
Conclusion
A technological leap in Generative AI (GenAI) is transforming society, enabling more efficient human interactions and streamlining numerous manual processes. For the Oil & Gas industry, adopting this technology stack is becoming essential to achieve unprecedented efficiency gains. The solution presented marks the first use of Text-to-SQL technology in the Oil and Gas domain, proving its effectiveness at scale in drilling applications. Designed to be generic, it is adaptable to various business contexts (e.g., production, subsurface) and Information Management Systems (OSDU, Cognite). By adjusting table definitions and domain-specific vocabulary, the solution presented can be adjusted to meet other specific business needs. With minimal to no training, drilling engineers can now extract critical decision-making information within seconds. Tasks that previously required software engineers’ weeks to implement can now be executed instantaneously, allowing for faster and more customized data access for end-users. By democratizing data access, this paper breaks down barriers for non-data professionals, empowering them to extract vital drilling performance metrics and make informed decisions. This capability ultimately optimizes operations and enhances overall efficiency.
Acknowledgements
We would like also to thank Aleksei Ivachev, Gregory McCardle and Artem Druchinin whose expertise has been valuable in successfully deploying and integrating this solution into production. We would like to express our sincere gratitude to Zheng Zhang and Xiqing Cheng from the AI LAB, SRPC Paris, France for their invaluable support and insights throughout this project.
References
- Victor Zhong, Caiming Xiong, and Richard Socher. 2017. Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning.
- Yu, Tao, et al. "Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task." arXiv preprint arXiv:1809.08887 (2018).
- Li, Jinyang, et al. "Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls." Advances in Neural Information Processing Systems 36 (2024).
- “Harnessing the Power of Data in Oil and Gas” BGC. MARCH 22, 2023
- OpenAI. Gpt-4o model, 2024.URL. Version 2024-05-13.
- Robertson, S., Zaragoza, H., et al. The probabilistic rele- vance framework: Bm25 and beyond. Foundations and Trends® in Information Retrieval, 3(4):333–389, 2009.
- Rahutomo, F., Kitasuka, T., Aritsugi, M., et al. Seman- tic cosine similarity. In The 7th international student conference on advanced science and technology ICAST, volume 4, pp. 1. University of Seoul South Korea, 2012.
- OpenAI. Ada 2., 2023. Accessed: 2024- 08-23
- Mandikal, P. and Mooney, R. Sparse meets dense: A hybrid approach to enhance scientific document retrieval, 2024. URL.
- Zhong, V., Xiong, C., and Socher, R. Seq2sql: Generating structured queries from natural language using reinforce- ment learning. CoRR, abs/1709.00103, 2017.