The Future of AI: Exploring Multimodal RAG Systems
Understanding the Basics: What is Multimodal RAG?
Multimodal RAG systems are advanced information retrieval and generation systems that go beyond traditional text-based approaches by incorporating and processing diverse data modalities, such as text, images, audio, and video. Below are some of the key features:
- Multimodal Data Handling: Process and integrate information from various data types, including text, images, audio, and video.
- Advanced Retrieval Techniques: Utilize vector databases, indexing, and chunking for efficient similarity searches and data management across different modalities.
- Augmented Generation: Leverage language models and vision encoders to generate richer and more informative responses, which may include text, images, and even video clips.
- Hybrid Search and Re-ranking: Employ sophisticated integration layers that combine different search and re-ranking strategies to improve the accuracy of retrieved information.
- Specialized Processing Pipelines: Optimize performance and accuracy for specific data types and queries by using dedicated processing pipelines tailored to each modality.
The Power of Multimodality: Why is it important?
The human experience is inherently multimodal. We process information from various sources simultaneously, forming a richer understanding of the world around us. Multimodal RAG mirrors this ability, enabling:
- Enhanced Comprehension: Combining different modalities can clarify ambiguities and provide a more holistic understanding of complex concepts.
- Improved Accuracy: Cross-referencing information across modalities leads to more accurate and reliable answers.
- Engaging Experiences: Incorporating images, videos, and audio creates more engaging and immersive learning and information-gathering experiences.
Challenges of Multimodal RAG Systems
- Data Complexity: Integrating and processing data from diverse modalities like text, images, and audio demands robust algorithms and significant computational power.
- Bias and Fairness: Ensuring fairness and mitigating biases embedded within each modality and their interactions is crucial for ethical and responsible AI.
- Ethical Considerations: As with any AI system, data privacy, responsible use, and potential misuse require careful consideration and mitigation strategies.
- Proprietary Data & Model Limitations: Pre-trained models, while powerful, are often limited by their training data. This restricts their understanding of specialized, proprietary data like technical diagrams or seismic imaging.
- Cross-Modality Representation: Achieving consistent and accurate representation of information across modalities is challenging. For example, aligning the semantic understanding of a chart in an image with its textual description in a document is vital for accurate retrieval and meaningful insights.
Implementation Techniques: How can we do it?
The goal is to embed various modalities, specifically images and text, into a unified vector space. This allows for seamless cross-modality search, enabling users to retrieve relevant information regardless of whether they're searching for text or images. We will focus on the two most common modalities – text and images – and explore three key approaches to achieving this. The table below represents the three most common techniques for embedding generation, retrieval, and synthesis for a multimodal RAG system.
| Technique | Embedding | Retrieval | Synthesis |
|---|---|---|---|
| Multimodal Retrieval and Synthesis | Multimodal embeddings for both images and text. | Text and Image embeddings similarity-based retrieval. | Multimodal LLM using raw images and text chunks. |
| Text-Centric Retrieval and Synthesis | Textual embeddings for raw text and image summaries. | Textual similarity-based retrieval. | LLM using text chunks. |
| Text-Centric Retrieval and Image-Centric Synthesis | Textual embeddings for raw text and image summaries. | Textual similarity-based retrieval (with reference to original image) | Multimodal LLM using raw images and text chunks. |
Table 1. Multimodal RAG Implementation Techniques
Unified Multimodal Embeddings
- Straightforward retrieval by enabling queries and responses in any one modality as shown in Fig 1.
- Facilitates easy implementation by swapping the embedding model in a text-based RAG with a multimodal counterpart.
Challenges:
- Training embedding models capable of capturing the intricacies and details of diverse modalities effectively is a complex undertaking.
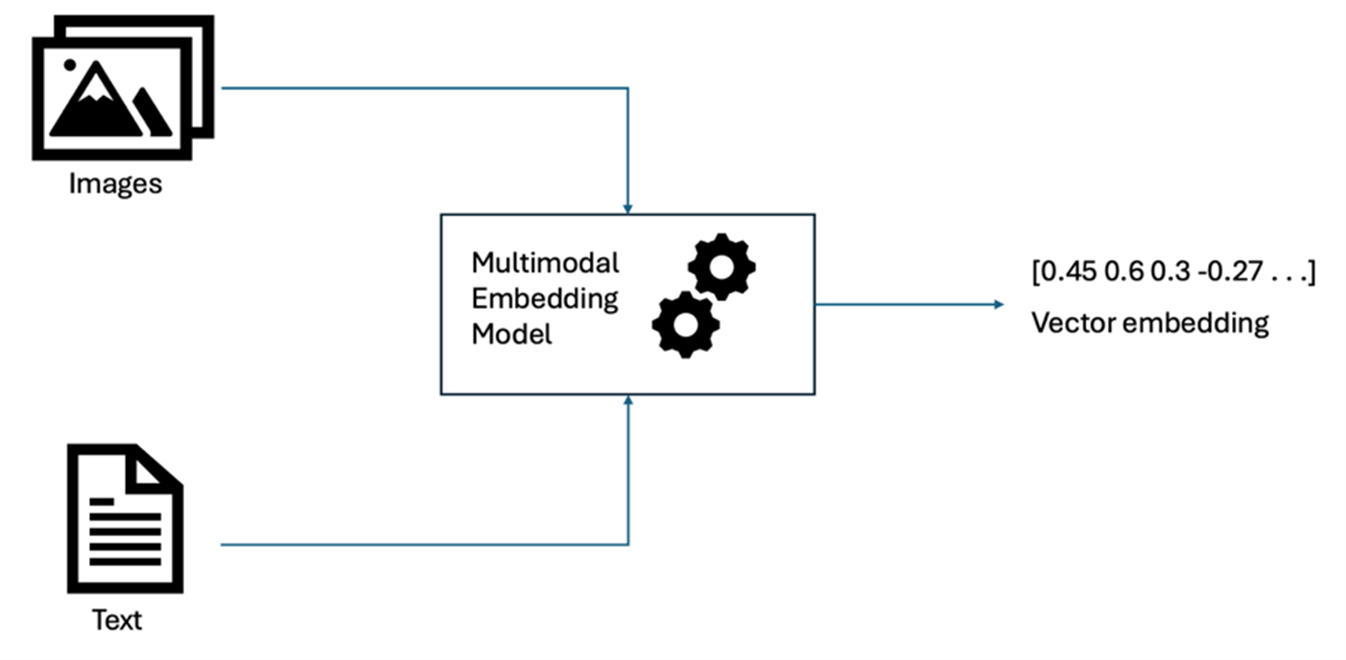
Fig 1. Unified Multimodal Embeddings
Grounding to a Target Modality
Convert all modalities into a single primary modality, typically text, for which robust embedding models exist. For example, you can generate text descriptions for images using image captioning models as shown in Fig 2, or by transcribing audio recordings.
Advantages:
- Leverages the maturity of text-based embedding models.
- Simplifies storage and retrieval within a single vector space.
Challenges:
- Potential loss of nuanced information during modality conversion.
- Incurring pre-processing costs for modality conversion.
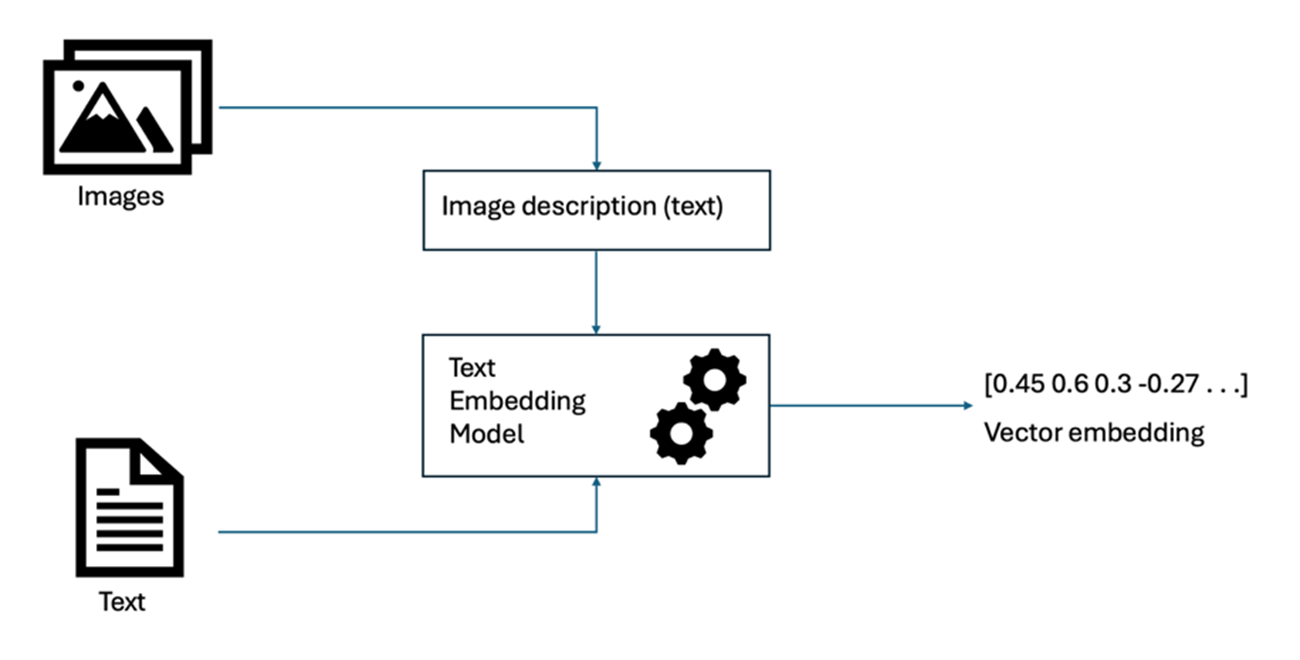
Fig 2. Grounding to Target Modality
Separate Vector Stores with Rank-Reranking
Employ specialized embedding models for each modality and store them in separate vector stores. Utilize a dedicated multimodal re-ranker to combine and rank results from each vector store. Advantages:
- Leverages the strengths of individual modality-specific embedding models.
Challenges:
- Increased complexity in implementing and managing multiple vector stores.
- Developing effective multimodal re-ranking algorithms.
Technology Development at SLB
Our latest technology innovation involves the development of a multimodal RAG system for various SLB unstructured data sources as shown in Fig 3. It integrates diverse data modalities by cleaning and processing them based on domain insights, converting them into embeddings, and storing those embeddings in a vector database. We are experimenting with a third option mentioned in the above table: Text-Centric Retrieval and Image-Centric Synthesis. We generate text embeddings for both text and images processed from documents but use the raw image along with the raw text during retrieval. User queries are also converted into textual embeddings and compared to the stored vectors, retrieving relevant information based on semantic similarity. This retrieved data along with user input provides a rich context for the underlying LLM to synthesize a comprehensive response, integrating insights from both modalities to generate a final output.
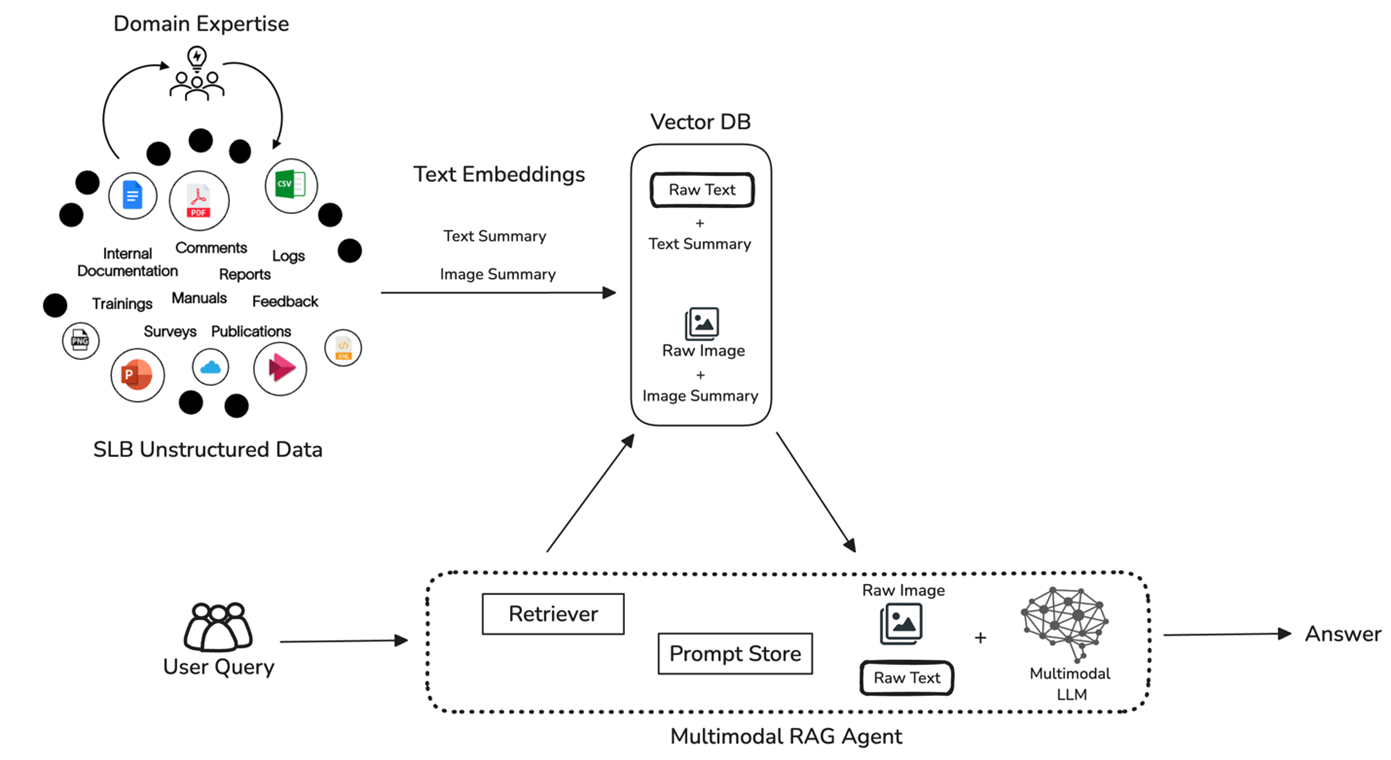
Fig 3. SLB Multimodal RAG System
Conclusion
The challenges of integrating and analyzing diverse geological domain data, often with varying scales, formats, and potential inconsistencies, pose significant hurdles in data alignment, interoperability, and quality control. Multimodal RAG represents a paradigm shift in how we interact with information. By embracing the power of multiple modalities, such as seismic data, well logs, geological maps, production data, and even satellite imagery, we can unlock new possibilities for deeper understanding and learning of insights embedded in our data. This technology holds the potential to revolutionize exploration and production by providing unprecedented insights and facilitating groundbreaking advancements.