Extracting drilling risks from Daily Drilling Reports using Generative AI
Employing Generative AI
We are now leveraging large language models (LLMs) to enhance our workflows, automating insights extraction, and improving risk identification accuracy. This has the benefit of overcoming some challenges with the conventional NLP approach. In this article, we demonstrate the results from different foundation models, both the cloud-based and on-premises models. We experimented with different strategies to address the hallucinations and knowledge cutoff concerns for a more reliable outcome. Our strategies were split into three stages:
Stage 1: Cloud-based model comparison, with prompt engineering, retrieval augmented generation (RAG), and fine-tuning. Stage 2: Fine-tuning 7B and 13B on-premises models Stage 3: Fine-tuning 7B and 13B on-premises models, adding SLB strategies for further model performance improvement.
We are applying this end-to-end pipeline to our workflow as illustrated below in Figure 1. The user can upload their documents in different formats, layouts, or languages to the application, and instruct the model to provide the structured output for their domain task. In this pipeline, we integrated domain-guided prompt engineering, domain knowledge retrieval and LLM fine-tuning.

Figure 1: End-to-end pipeline from unstructured documents to structured outputs.
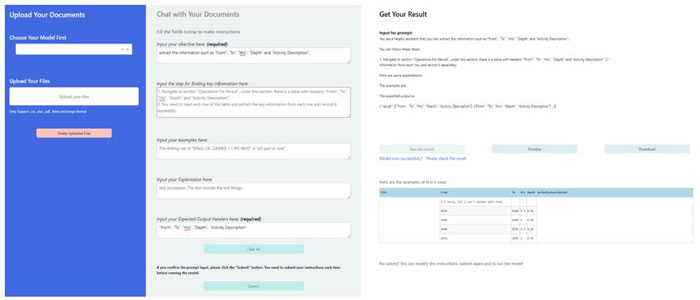
Figure 2: Chat with Doc Web Application Demo Interface.
Model Performance Evaluation
We assessed model performance and effectiveness using classification evaluation metrics, such as accuracy, precision, recall, and F1 score, within the context of human evaluation benchmarks, by comparing the prediction output with the domain expert’s labels. The current adaptation of LLMs employing prompt and RAG techniques represents a significant leap forward compared to earlier NLP approaches (Priyadarshy, S., et al., 2017; Zhang, Z., et.al., 2022) or a previously fine-tuned oil and gas GPT-2 model we use as benchmark (Marlot, M., et.al., 2023).
Figure 3 below illustrates the validation dataset and the imbalance distribution of drilling events from historical reports, which is a common challenge for this use case. Conventional machine learning models often struggle with the imbalance of target label distribution. The fine-tuned GPT-2 model performs adequately for major drilling classes, but it struggles with rare classes primarily due to the limited examples available for training. With a larger cloud-based model, the model exhibits improved generalization and reliability for both frequent and infrequent drilling events.
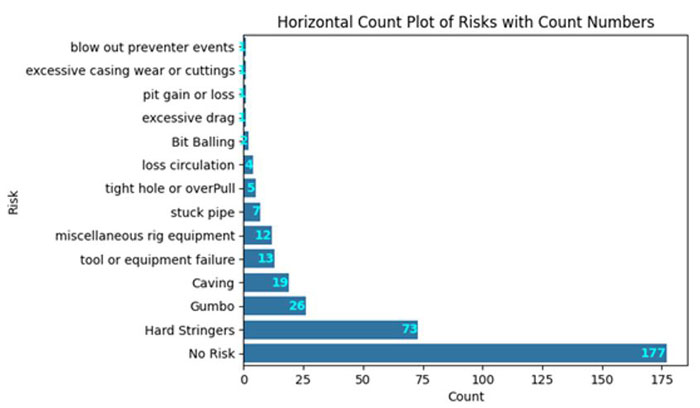
Figure 3: Validation Datasets Consists of 13 Classes of Drilling Risks
We then further fine-tuned both cloud-based and on-premises language models and were able to achieve better results, with proper fine-tuning techniques. From the study, we demonstrate the potential to develop a cost-effective, and high-accuracy model with limited resources. After combining our SLB strategy, by adding domain knowledge when we fine-tune the on-premises language model, our result outperforms the fine-tuned cloud-based model.
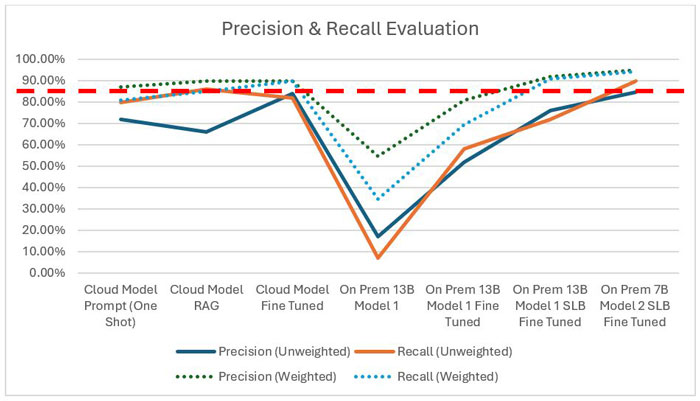
Figure 4 - Precision & Recall Evaluation (Weighted - emphasize on major class, Unweighted - treat all class equally). The red line represents the engineer workflow acceptance threshold, which should be greater than 85%.
Table 1 Model comparison table with a human benchmark evaluation *Weighted score - emphasize on major class *Unweighted score - treat all class equally
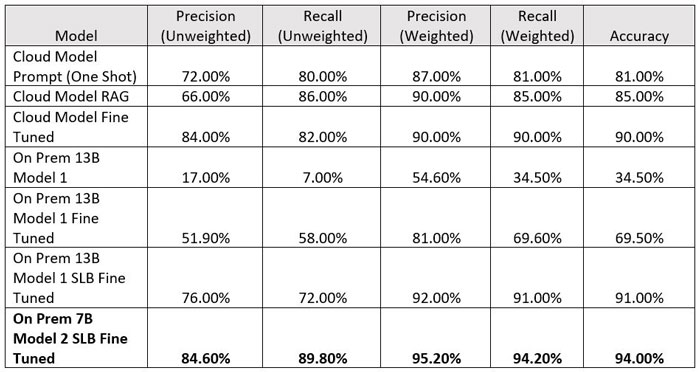
The results indicate that the weighted metrics for the major drilling class remain consistent across different LLM models, while the unweighted metrics, which assign equal importance to infrequent drilling events, vary. This suggests that when evaluating LLM efficiency, models that demonstrate substantial improvement in unweighted metrics are preferred, as machine learning models often struggle to generalize with limited training samples. From the results, we observed fine-tuning smaller models with proper techniques could outperform the cloud-based models.
This gives us a hint that the model size may not be an indicator of how good the model is performing. Even the 7B model could outperform the 13B model as shown in Table 1 and Figure 4, given appropriate fine tuning and domain data that we feed in when we fine tune the model.
Realized Value
This approach was implemented in a field with 24 wells. Hidden risks are embedded in 180 DDR reports from these fields, where hidden risks are defined as events that are labelled ‘OK’ (as opposed to non-productive time (NPT)) but where the comment reveals issues that were not being captured as NPT. In this dataset, nearly 85% of the remarks were classified as potentially “hidden” as they were not labelled NPT. To spot them, the engineer would need to manually read and identify them. The drilling reports were all initially parsed and manually labelled by an engineer with the appropriate risk category. We then evaluated the predicted drilling remarks against the engineering labels from manual reading and followed up with manual validation from the drilling engineer on the prediction outputs, where there is a discrepancy.
The best performing LLM model in this case was shown to be the on-premises 7B model after fine-tuning with the SLB approach, it is then looked at more closely. From the results, we can see the prediction results are a 94% match of the provided engineering labels, just 6% are different, as shown in the pie chart below.
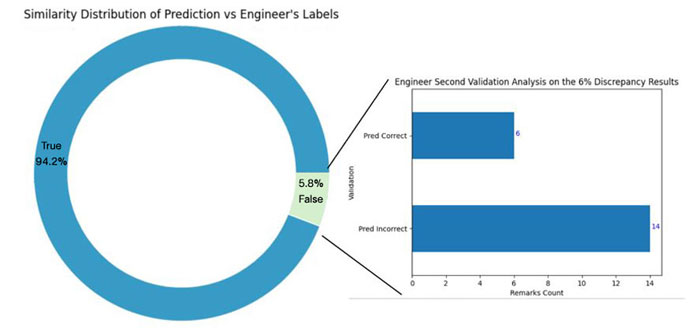
Figure 5: Out of 342 validation remarks, 94% of the engineering labels matched with the model prediction. The remaining 6% discrepancy results went through a second round of validation from the drilling engineer. Six of these were validated with correct model prediction, and 14 were incorrect. The total accuracy achieved after the second validation is near 96%.
We then performed a further analysis, to investigate the predictions that did not align with the given labels. From this validation, within the 20 remarks (6%) from the validation dataset, six of them were predicted correctly, three of them were mislabeled with an incorrect hidden event class and three of them were entirely overlooked by the engineer. The model incorrectly predicted 14 of these remarks, and this is where we are now focusing our improvement efforts.
Assuming a reading speed of six reports per day, engineers may spend up to one month to discover hidden risks manually. However, with automation we can process each report in half a second on GPU A100. The discovery of these events only consumes approximately 1.5 hours, this process is also highly parallelizable.
In general, we see LLM models performing very well and, on this test set they are on par with human accuracy, but several orders of magnitude faster. After our second validation, the LLM models successfully achieved nearly 96% accuracy on the imbalanced training dataset, which was not previously achievable with state-of-the-art NLP models or with models like GPT2. This gives us confidence that deploying these models alongside humans will yield business value at the current level of technology.
Way Forward
This result only gives us a snapshot of the current level of performance, and we are continuing to incorporate reinforcement learning with human feedback (RLHF) from domain experts, improving the fine tuning, running more suitable models, and improving prompting which will push model performance way beyond current levels applied to more diverse datasets.
Besides, with the rapid ever-evolving landscape of generative AI, we need to be able to adapt our strategy quickly to these. In SLB, we can do so by leveraging our data and AI platform. It supports continuous experimentation with the new models. Once we build confidence after experiments, we are committed to scaling and integrating with our domain software seamlessly, allowing our everyday domain users to incorporate generative AI into their daily domain workflow.
References
- Marlot, M., Srivastava, D. N., Wong, F. K., & Lee, M. X. (2023, October). Unsupervised Multitask Learning for Oil and Gas Language Models with Limited Resources. In Abu Dhabi International Petroleum Exhibition and Conference (p. D021S065R005). SPE.
- Priyadarshy, S., Taylor, A., Dev, A., Venugopal, S., & Nair, G. G. (2017, May). Framework for Prediction of NPT causes using Unstructured Reports. In Offshore Technology Conference (p. D041S046R006). OTC.
- Zhang, Z., Hou, T., Kherroubi, J., & Khvostichenko, D. (2022, March). Event Detection in Drilling Remarks Using Natural Language Processing. In SPE/IADC Drilling Conference and Exhibition (p. D022S007R002). SPE.