Foundational Model – A Multitask Adaptable Model for Wellbore Analysis
Foundational Model – A Multitask Adaptable Model for Wellbore Analysis
Envision a single neural network (NN) application that can be quickly adapted to address various log analyses, each with a fast turnaround and low computational cost. To achieve this goal, we are developing a suite to enable such capabilities and potentially reshape the future of log analysis workflow.
This solution considers the presence of inconsistencies and missing data which commonly occurs in wellbore log analysis, and we propose a deep learning training strategy to enable well log analysis and interpretation in these challenging scenarios.
Recent developments in machine learning and artificial intelligence (ML/AI) allow us to target a unified approach for addressing log-related analysis. The foundation models are large, deep neural networks trained using self-supervised paradigms (i.e., no labels) and multitasking methods, which can capture the wide fundamental characteristics of the data at hand as indicated in Figure 1.
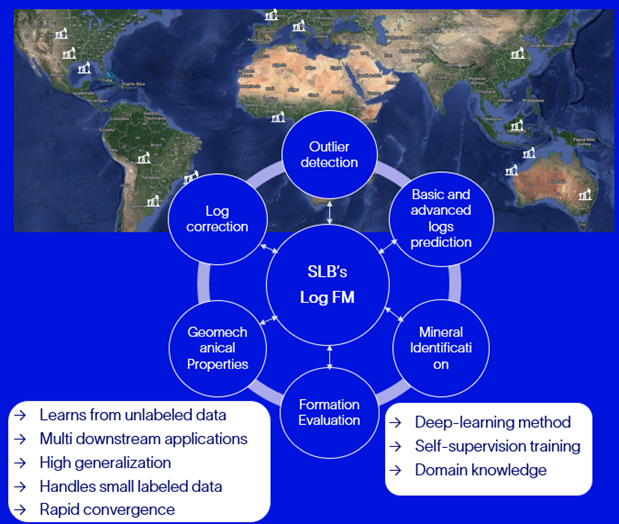
Figure 1: The primary concepts for building a large pre-trained model for wellbore log applications, adaptable for multiple downstream application and multiple formation types.
Once trained, one can rapidly fine-tune such foundation models for a multitude of downstream tasks, such as formation evaluation, geomechanical properties estimation, zonation, marker detection, missing log prediction, and outlier detection, with the advantage of requiring far fewer labels and lower training complexity as indicated in Table 1.
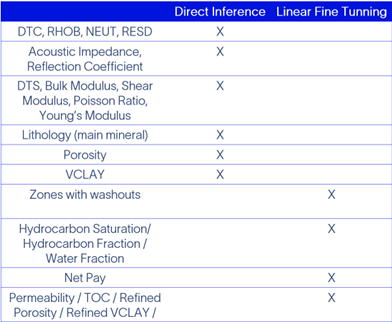
Table 1: List of downstream applications for direct inference or linear fine tuning.
During the development of this foundational model, we collected and cleaned wellbore log datasets from different locations, that we are using to build a pre-trained large for log applications, and we observed that it provides robust, accurate, and quick turnaround time, with signs of generalization, diversity capture, and transfer learning capabilities. Employing pretrained foundational models reduced workflow complexity and the time associated to build log applications. Much care is exercised when building this foundational model - we focus on quality, stability, and computational efficiency as well as improving usability. This allows us to build customizable workflows to provide a smart petrophysical assistant with access to a large pool of data, with the intent to increase the assistant capabilities to include the knowledge of geologists and upgrade it to a cross-discipline geoscientist assistant.
Compared to traditional methods, fine-tuning pretrained models for specific tasks provides good-quality results using fewer training examples. Traditional approaches aim to solve one specific task for a particular location. The same is true of the current popular trend of building individual ML models. Such procedures require substantial dedication by domain experts to select, clean, and label (interpret) the wellbore logs. Furthermore, a high-computational cost is incurred to train individual models, and they are not transferrable to other tasks or geologies. To alleviate such shortcomings and arduous steps, SLB’s logFM will allow the launch of these tasks rapidly and with fewer labels using the basic logs as input to the model as indicated in Figure 2.
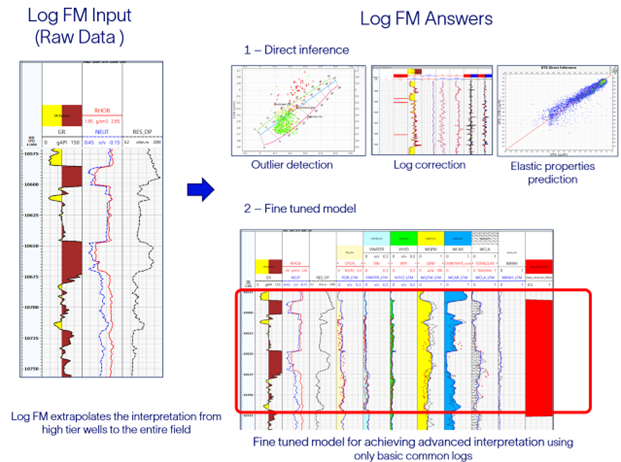
Figure 2: Examples of work steps enabled by large models to provide quality control and formation evaluation answers.
SLB’s log FM unifies the log analysis workflow – it provides a single platform to enable a cosmos of log applications around a monolithic foundation model, and it brings together several key elements including the following:
- The foundation model can be a centerpiece to enable a petrophysical assistant to provide multiple log related answers
- The inclusion of subtle log-related nuances in how we train foundation models in an unsupervised manner
- Additional general training approaches to ensure robust capture of the underlying log characteristics during the foundational build
- Simultaneously providing confidence analysis for various tasks
- Value user privacy and data protection, and allow the users to maintain a library of private models to learn from new data and examples
Multiple steps in the log analysis workflow rely on large deep learning models and are built in a fashion to be easily applied orchestrated by agents capable of executing subtasks. These agents execute and optimize complex workflows adaptable for different data quality issues and end-applications. This data richness allows for the integration between different platforms to improve the information extraction from available databases.