Beyond Pixels and Words: The Power of CLIP in Fusing Vision and Language
Introduction
Imagine a world where geoscientists can effortlessly extract insights from complex subsurface visual data simply by asking questions in plain language. This future is rapidly approaching thanks to advancements in Vision Language Models (VLMs). By bridging the gap between the visual and textual domains, VLMs are revolutionizing industries, including the critical realm of subsurface resources.
At the heart of these powerful models lies a family of contrastive learning approaches pioneered by Contrastive Language-Image Pre-Training (CLIP). By teaching models to understand the relationship between images and text, CLIP has unlocked a new frontier of possibilities. But how does CLIP truly work, and why is it a central component in many VLM applications? What does it mean for the subsurface industry? In this article, we delve into the mechanics of CLIP and explore its potential to transform how we explore and develop our planet's resources.
VLMs and Semantic Search in Subsurface Software Applications
It no longer feels like magic when AI generates hyper-realistic images from simple text prompts or provides detailed descriptions of complex visuals. VLMs have undoubtedly revolutionized how we interact with data. However, despite their impressive capabilities, these models often struggle to understand the nuances of specialized domains like subsurface exploration. To overcome these challenges, industry-specific ML-training and meticulous data curation are essential. With the right approach, VLMs can be harnessed for a multitude of subsurface applications, including generating realistic subsurface models, automatically describing complex images for reports, answering questions about visual data, and enabling intuitive data exploration through natural language queries.
Imagine a subsurface AI data assistant powered by domain-trained VLMs that seamlessly integrates with your workflow (Figure 1). . This intelligent assistant can generate realistic seismic images based on textual descriptions, automatically generate informative captions for complex datasets, and retrieve specific data slices with the precision of a seasoned geologist using simple language queries (Figure 1). For instance, you could request a "seismic 2D line with rotated fault blocks in the Norwegian Continental Shelf" or "find the gas chimneys in this 3D survey." These VLMs unlock new possibilities for exploration, production, and reservoir management by understanding the nuances of subsurface data and terminology.
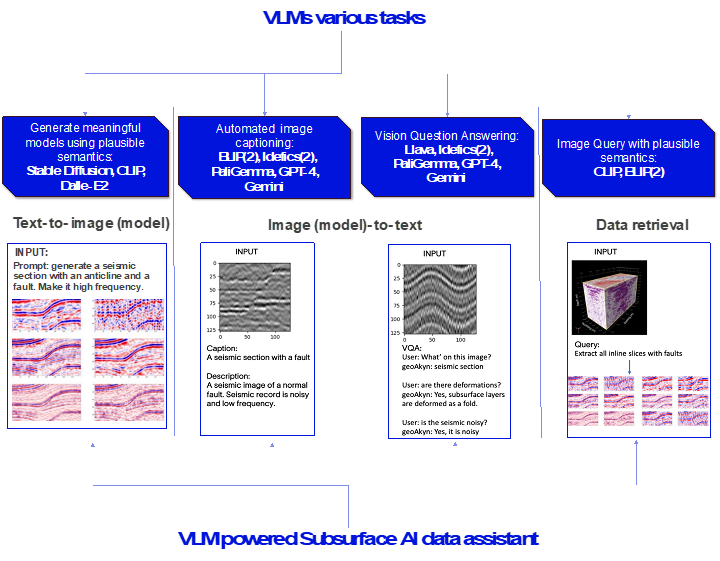
Figure 1. VLM-powered Subsurface AI data assistant use cases with potential model architectures.
CLIP Family. Bridging Visual and Text for VLMs
VLMs need to connect visual and language information strongly. To achieve this, a type of machine learning called contrastive learning is used to teach models to understand both images and text together. A groundbreaking model in this area is CLIP, followed by others like SigLip, BLIP, and OpenCLIP. For simplicity, we'll refer to this group of models as "CLIP." Let's examine popular text-to-image and image-to-text models to see why CLIP is crucial.
Text-to-image. Figure 2 demonstrates a general overview of the architecture we used to create our own text-to-subsurface model. The architecture is from the work of Aditya, et al. from 2022. At a high level, architecture works as follows:
- First, a text prompt is input into a text encoder that is trained to map the prompt to a representation space.
- Next, a model called the prior maps the text encoding to a corresponding image encoding that captures the semantic information of the prompt contained in the text encoding.
- Finally, an image decoder stochastically generates an image, which is a visual manifestation of this semantic information.
As you notice, CLIP is one of this architecture's central components, as it links image and textual representation.
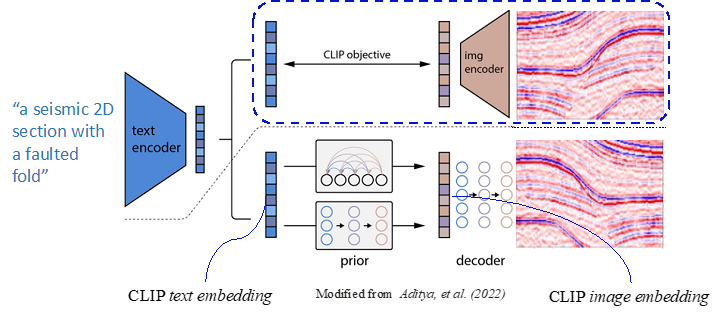
Figure 2. Popular unCLIP text-to-image architecture with CLIP as a core component (Aditya, et al., 2022)
SLB leveraged the unCLIP model, a state-of-the-art text-to-image architecture, to develop geoGen, an application for generating meaningful subsurface representation with text prompts (Figure 3). Trained on synthetic seismic and geological datasets, geoGen can generate realistic subsurface images based on semantically plausible user prompts. For instance, domain experts can use various synonyms of the same geological object, such as 'normal fault' or 'extensional tectonics,' to construct their prompts freely.
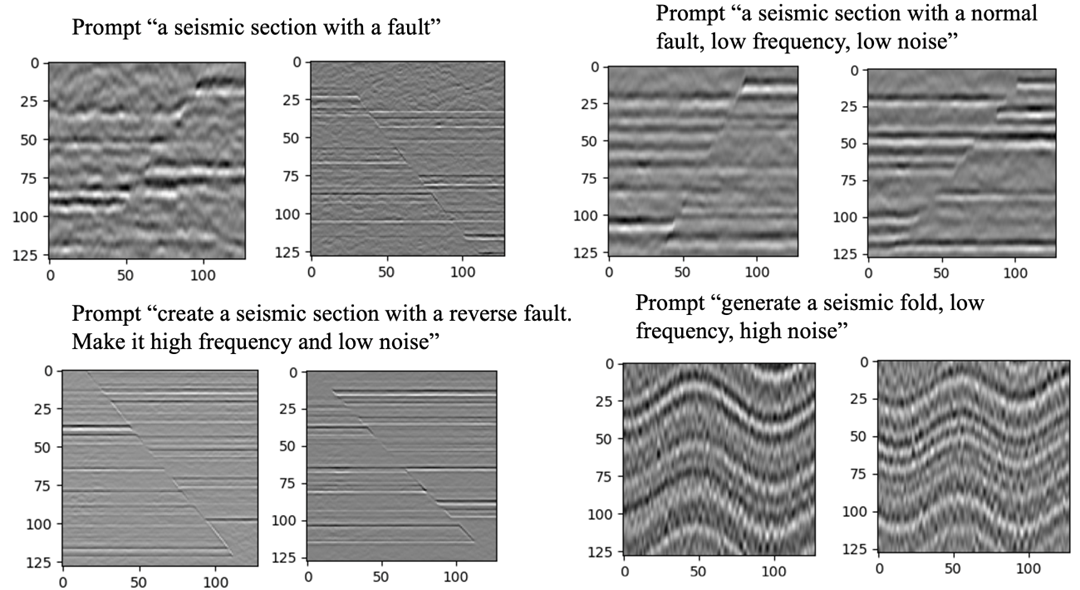
Figure 3. Text-guided seismic images generated by geoGen.
Image-to-text. Figure 4 depicts a popular image-to-text architecture called Idefics2 (Laurencon et. el, 2024). According to this architecture, “Input images are processed by the Vision encoder. The resulting visual features are mapped (and optionally pooled) to the LLM input space to get the visual tokens (64 in our standard configuration). They are concatenated (and potentially interleaved) with the input sequence of text embeddings (green and red column). The concatenated sequence is fed to the language model (LLM ), which predicts the text tokens output.”
While Idefics2 does not explicitly incorporate CLIP, it's noteworthy that CLIP models, particularly SIGLIP, have demonstrated superior performance as vision encoders within this architecture. This highlights the versatility and effectiveness of CLIP in various visual-language tasks.
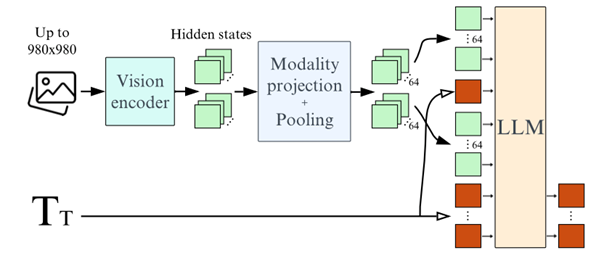
Figure 4. Idefics2 fully-autoregressive architecture. CLIP is a default choice for a vision encoder.
Indeed, CLIP is so popular because it learns the link between textual semantics and their visual representations. Original CLIP is trained on hundreds of millions of images and their associated captions, learning how much a given text snippet relates to an image. Rather than trying to predict a caption given an image, CLIP learns how related any given caption is to an image. This contrastive rather than predictive objective allows CLIP to learn the link between textual and visual representations of the same abstract object. Thus, CLIP serves as a versatile tool with applications beyond core VLM functions like text-to-image and image-to-text generation. Its ability to establish robust semantic connections between visual and textual data also makes it highly effective for multimodal semantic search.
Semantic search. Imagine an exploration team grappling with hundreds of 2D and 3D seismic surveys for resource assessment. Traditionally, pinpointing specific subsurface features like DHIs (Direct Hydrocarbon Indicators) or pinch-outs involves a thorough manual examination of terabytes of data. This process is time-consuming and requires specialized expertise. By leveraging a CLIP-powered semantic search, teams can dramatically accelerate this process. With simple text prompts like 'all slices with DHIs' or 'extract seismic sections with pinch-outs,' relevant data can be retrieved within seconds. Moreover, this technology extends beyond text-based queries, enabling image-to-image searches for visual pattern recognition inside the user’s huge data massifs.
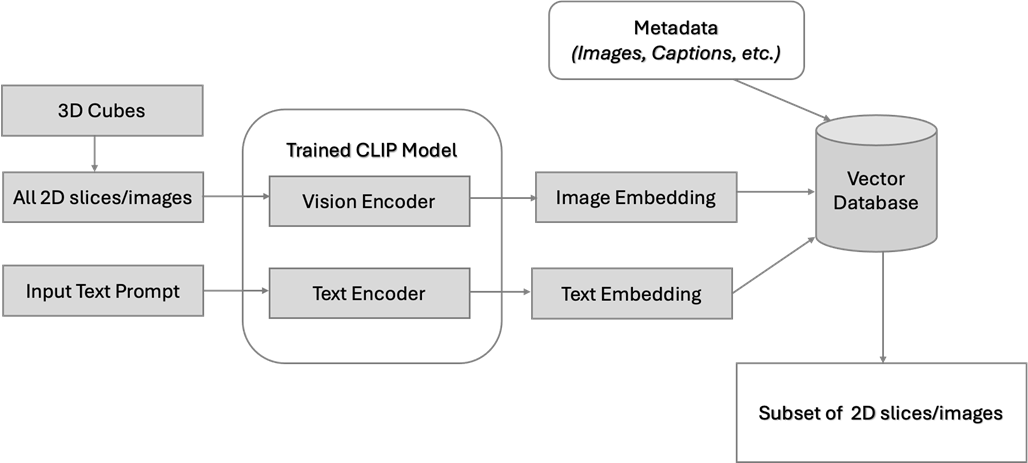
Figure 5. Semantic seismic image query and similarity search design
How CLIP works
To grasp the essence of CLIP, let's dissect its acronym: contrastive, language-image, and pre-training (Figure 4, 5).
Language-Image. CLIP is designed to handle both language (text) and images simultaneously. To achieve this, CLIP employs two encoders: one for text and another for images. These encoders convert the input data into numerical representations called embeddings, which are essentially mathematical descriptions of the data. CLIP maps both text and images into the same numerical space, allowing for direct comparisons between the two.
Contrastive. Merely embedding text and images in the same space isn't enough. CLIP introduces a technique called contrastive learning to establish meaningful relationships between these embeddings. The model is trained to bring embeddings of related image-text pairs closer together while pushing apart embeddings of unrelated pairs. This process helps the model learn subtle nuances and similarities between the visual and textual worlds.
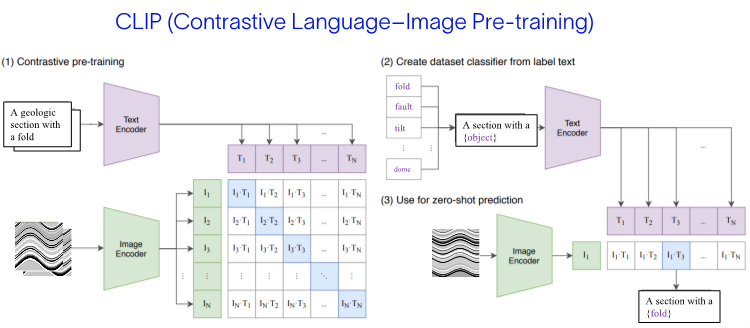
Figure 6. CLIP architecture from, modified from Radford et al., 2021
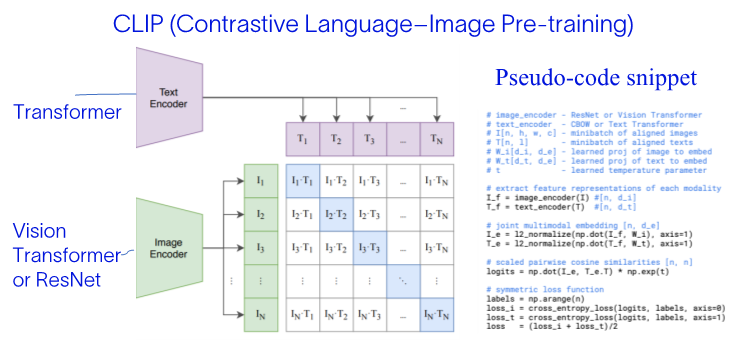
Figure 7. CLIP architecture from, modified from Radford et al., 2021
Pretraining. CLIP models are typically trained on vast amounts of image-text data, a process known as pre-training. This foundational knowledge allows CLIP to be adapted to various tasks without needing to start from scratch. For instance, CLIP can be used for image classification without additional training data (zero-shot learning). Additionally, as noted, it serves as a building block for more complex models like Stable Diffusion and DALL-E, which generate images based on text descriptions and vice versa.
The CLIP training is quite straightforward (Figure 7):
- All images and their associated captions are passed through their respective encoders, mapping all objects into an m-dimensional space. In the original paper, the text encoder is a classic Transformer, and the vision encoder is either a Vision Transformer or ResNet.
- The cosine similarity of each (image, text) pair is computed, as shown in the pseudo-code snippet.
- The training objective is to simultaneously maximize the cosine similarity between N correct encoded image/caption pairs and minimize the cosine similarity between incorrect encoded image/caption pairs.
Better to Data than Not
Above, we demonstrated how CLIP combines text and images (or other visuals, such as seismic data) into one numerical space. It is then used as a tool in text-image vector search or as a core component for VLMs.
Originally trained on vast datasets of public image-caption pairs, CLIP is often considered a standard choice for off-the-shelf text-image encoding and semantic search. However, our experiments demonstrate that VLMs trained with CLIP models pre-trained on domain-specific image-caption pairs significantly outperform those simply fine-tuned on domain data. This highlights the importance of tailoring the pre-training process to the specific application domain.
Figure 8 compares the inference time performance of two geoGen models: one trained with CLIP simply fine-tuned on subsurface data and another trained with CLIP using a domain-specific pre-trained image and text encoder. As demonstrated, some complex text prompts, such as 'fold with low frequency and low noise,' can lead to incorrect image generation in the geoGen model with a default fine-tuned CLIP. For example, such a prompt might generate a monocline or tilted layers rather than the desired anticline. However, when CLIP is trained on pre-trained image and text encoders, the semantic information between the two modalities is captured more accurately, resulting in more precise and relevant image generation. Let’s dive into how this generation problem may happen.
To illustrate the importance of domain pre-training, we plotted image and text embeddings in a 2D t-SNE plot, clustered by subsurface object classes (Figure 9 and 10). We used a total of 35 subsurface classes, represented in the legend of both figures. For the image embeddings, we clustered 45,000 samples, color-coded them by object class name, and plotted them on a t-SNE plot.
Figure 9 shows the results using an off-the-shelf CLIP image encoder. In this case, the clusters are often combined, connected, and difficult to distinguish. In contrast, Figure 10 shows the results using an image encoder pre-trained on subsurface images. Here, the clusters are well-separated and almost perfectly clustered, demonstrating a stronger semantic connection between text and image.
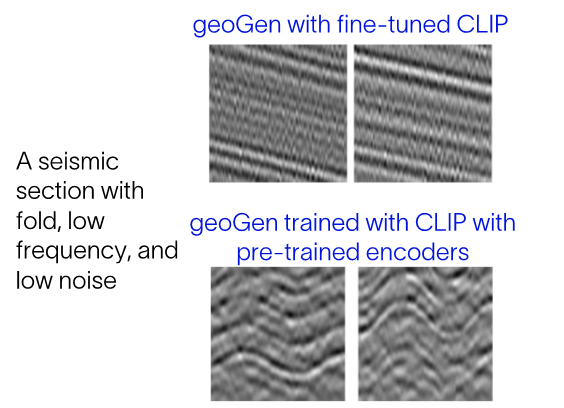
Figure 8. A comparison of text-to-image subsurface generative model geoGen with (bottom) and without (top) pre-trained image and text encoders
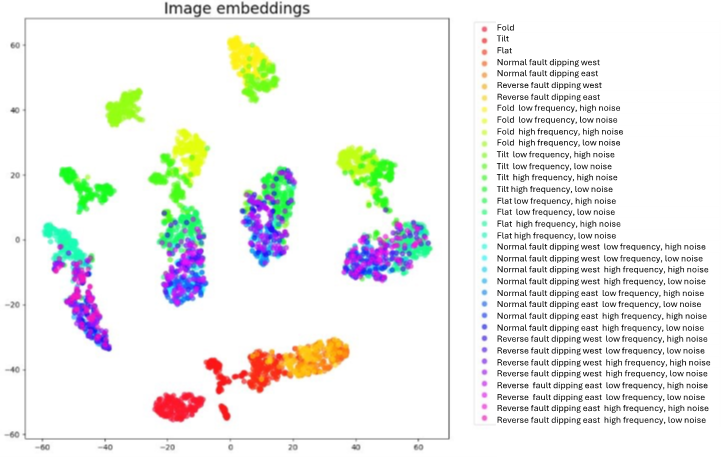
Figure 9. t-SNE image embeddings plot without image encoder pre-training
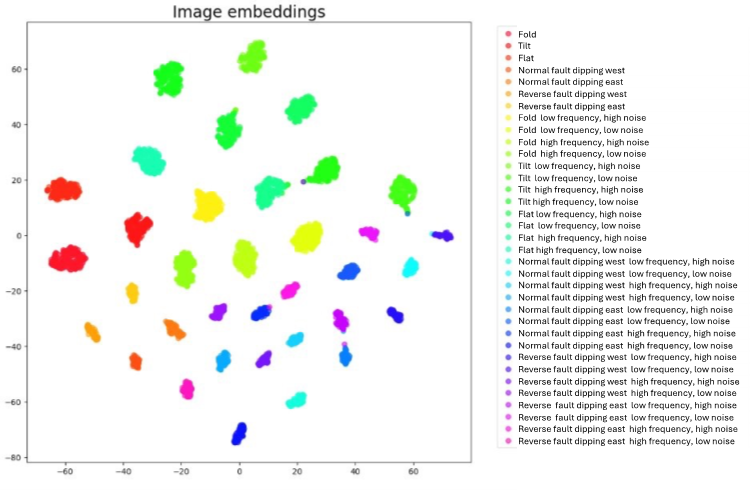
Figure 10. t-SNE image embeddings plot with image encoder pre-training
To quantify the importance of image encoder pre-training for CLIP models, we calculated the inference accuracy on a test set of 4000 image-caption pairs. We used both a default fine-tuned CLIP model and a CLIP model with a pre-trained image encoder. For the seismic image classification task, we employed simple prompts like 'Show me a seismic section with a normal fault' and more complex prompts like 'Give a seismic section with a normal fault dipping east with high frequency and low noise.' Our experiments demonstrated a significant increase in accuracy, from 45% to 99%, when using a CLIP model with a pre-trained image encoder.
To achieve optimal performance in image semantic search using text prompts, we strongly recommend training CLIP-family models with domain-specific pre-trained image and text encoders. As our experiments have demonstrated, this approach can significantly improve the accuracy and relevance of search results by capturing the unique semantic relationships within subsurface domain.
Conclusion
CLIP-family models have emerged as a cornerstone of VLMs, offering a powerful tool to bridge the gap between visual and textual data. By teaching models to understand the relationship between images and text, CLIP has unlocked a new frontier of possibilities, particularly in the subsurface industry. As we've explored in this article, CLIP's ability to extract insights from complex visual data through simple language prompts has the potential to revolutionize how we explore and develop our planet's resources.
By leveraging CLIP-based VLMs, geoscientists can gain deeper insights from seismic data, automate and optimize exploration and production processes. As these models continue to evolve, we can expect even more groundbreaking applications that will drive innovation and sustainability in the subsurface industry.