Beyond Accuracy: Building Better, Safer, and More Reliable LLM Systems
Input Guardrails
Utilizing LLMs in real-world applications presents significant challenges, particularly in managing inappropriate or harmful inputs. Unlike traditional applications with controlled and finite input parameters, LLMs struggle with the unpredictable and subjective nature of natural language. This has led to various attacks, including prompt injection, jailbreaking, and data leakage. The industry is actively working to address these challenges.
Basic rule-based filters, using regular expressions and keyword lists, serve as an initial defense against harmful content. Content moderation tools, such as OpenAI's moderation bot, offer a model-based approach to detect and filter inappropriate or offensive content. Many LLMs incorporate these general-purpose moderation tools for protection. Guardrail frameworks, like Nvidia's NeMo guardrails, have emerged to leverage LLMs for filtering unwanted content. These frameworks enable the development of custom filtering schemes, making them suitable for domain-specific applications. While efforts have been made in industries like legal, finance, and education, the energy industry faces unique safety challenges due to its specialized terminology and the extremely sensitive nature of the data we operate on.
To address these challenges, we have developed an input guardrail system that filters and manages inputs before they are processed by any LLM application. This ensures that the generated outputs are both safe and contextually appropriate. Our system demonstrates SLB's ability to build robust solutions despite the technical challenges and limited industrial maturity of off-the-shelf technology.
SLB Guardrail System
Designing and building robust domain-specific guardrails requires a meticulous approach. The main components of building such a system are:
- A user input policy
- Implementation Framework
- Workflow Integration
Of the three, the most critical aspect is crafting a comprehensive input policy that defines what is allowed and what is not. This policy needs to be carefully tailored to the specific needs of the downstream workflow, ensuring it blocks irrelevant requests, harmful content, security threats, and malicious attempts. The policy's effectiveness hinges on its ability to seamlessly integrate with the LLM's input evaluation process, requiring careful tuning to avoid inconsistencies. Hence, we take a careful iterative approach to addressing the unique challenges of the energy domain. Through multiple cycles of refinement, we have designed a policy to block any irrelevant requests, harmful content, security risks, and malicious attempts, allowing the application to function as intended. The policy requires careful tuning, given that it is used by an LLM to evaluate inputs, which is overly sensitive to minor changes in the prompt.
The choice of framework, while interconnected, is designed to foster modularity, and facilitate application across various domains. Our guardrail system functions as a standalone module, allowing any LLM-based application to easily incorporate it. As can be seen in the figure below, the user input is passed through the guardrail system, receiving a sanitized output that indicates compliance with the usage policy. This modular design ensures consistent implementation of essential safety features, eliminating the need for repeated development across different applications. Moreover, any company-wide policy changes can be efficiently updated in a single service, reducing redundancies, delays in adoption, and potential inconsistencies.
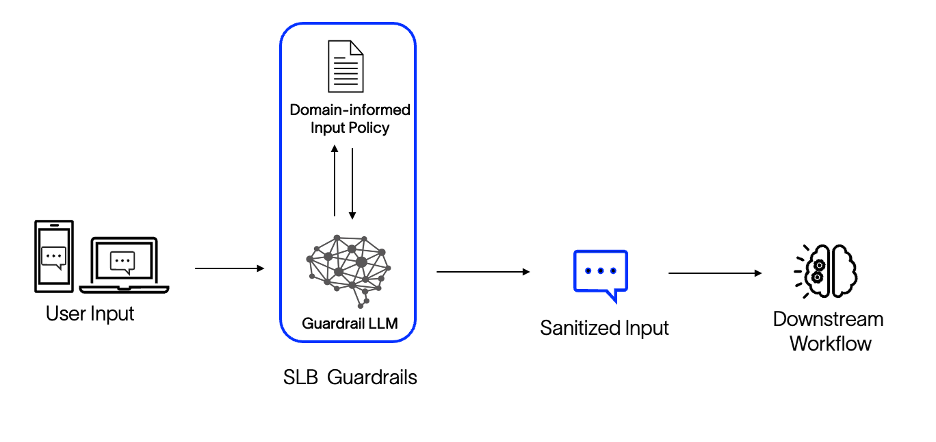
Fig 1. SLB Guardrail System
It is, however, important to note that as with all ML (Machine Learning) model-based systems, these guardrails are not foolproof. While they offer strong protection against malicious and inappropriate usage, there is always a risk that attackers may find newer jailbreak methods that go through undetected. Therefore, the system must also be kept up to date and tested frequently to ensure safety.
Overall, our guardrails approach not only enhances the reliability and safety of LLM deployments but also aligns with ethical guidelines and regulatory requirements, providing a robust solution for industries that demand high standards of content moderation and user interaction. This is achieved through a careful focus on the needs and use cases and using our insights in the domain to identify key challenges in the field.
Robust Benchmarking
Despite the rapid progress of LLMs, their development often lacks the rigorous quality control needed for highly specialized fields. Evaluation and benchmarking are the pillars of safe and reliable systems, and available frameworks often fail to provide our domain's needs. RAG systems, for instance, do not have any energy-related benchmarks available.
We will now explore in detail the benefits of domain-focused evaluation and benchmarking, focusing on key RAG components to optimize, the creation of domain and product-specific benchmarking datasets, and the metrics used to assess performance. Finally, we bring together these ideas through a case study that we conducted at SLB for benchmarking and improving the RAG system for SLB products.
Benchmarking involves evaluating a system's performance on standardized datasets and tasks, allowing for:
- Performance Measurement: Quantifying how well the system retrieves and generates information.
- Component Optimization: Identifying which parts of the system need refinement and improving them.
- Quality Assurance: Ensuring the system meets predefined standards of accuracy, relevance, ethical, and safety standards.
- Performance Tracking: Monitor progress over time and measure the impact of modifications.
The diagram below provides an overview of the RAG system workflow, which begins with document ingestion, where an enterprise knowledge base is processed and transformed into a format suitable for retrieval. This involves preprocessing documents and creating document embeddings. These embeddings are then stored in a vector database.
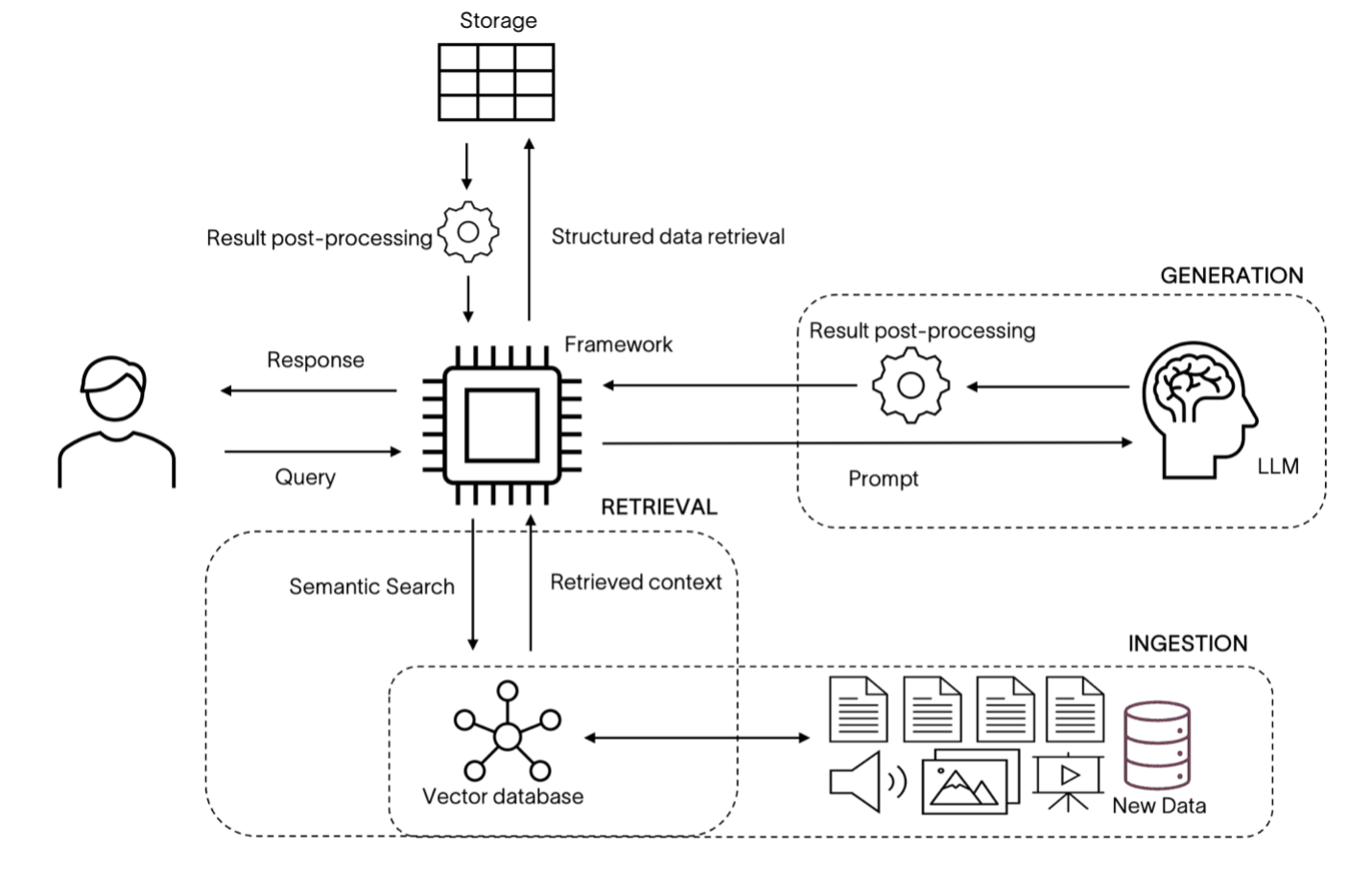
Fig 2. RAG System
When a user submits a query, the system performs retrieval in the embedding space for the most relevant documents, which are then combined with the query to form a contextually enhanced prompt. This prompt is fed into an LLM that generates a text response based on the provided information and its knowledge. Based on the workflow described, we identify the following main aspects to optimize the retrieval and generation.
Retrieval Component
The retrieval component of an RAG system is responsible for fetching relevant information from a large corpus. Key aspects to optimize in the retrieval component include:
- Document Chunking: Through benchmarking, varied sizes and strategies for chunking and length of overlap can be tested to determine the optimal values, controlling granularity and contextual continuity.
- Embedding Model: The choice of embedding model affects how well the system understands and retrieves contextually relevant information. Benchmarking can be leveraged to select the best model through the evaluation of both pre-trained and fine-tuned embedding models.
In addition, benchmarking can also help evaluate the impact of query expansion or reconstruction techniques and different pre-filtering criteria on the retriever results.
Generation Component
The generation component uses the retrieved information to produce coherent and contextually appropriate responses. Key aspects to optimize include:
- Large Language Models (LLMs): LLMs have varying capabilities in terms of fluency, coherence, and contextual understanding. Benchmarking helps in selecting the most suitable model for a given task. In addition, it can also be used to evaluate fine-tuned models on specific tasks to improve performance.
- Prompt Structure: The way information is presented to the LLM significantly impacts output quality. Benchmarking helps optimize prompt structure, including the use of instructions, examples, and context delimiters.
- Generation Parameters: Decoding parameters such as temperature, max tokens, and top-p significantly influence the factuality and relevance of the generated text. Benchmarking helps find the optimal balance for the specific task or application.
Benchmarking Dataset Creation
Creating a high-quality domain-specific benchmarking dataset with relevant tasks is crucial for meaningful evaluation. We adopt ideas of Self-Instruct and Evol-Instruct, which leverage LLMs to automatically generate diverse and challenging questions and answers based on a few-shot examples in the provided context. The approach starts with a set of manually crafted seed tasks and expands them using techniques like paraphrasing and data augmentation.
For our internal evaluation of the SLB product RAG, we create the domain/product-specific benchmarking data in the form of (Ground Truth Context, Question, Answer) triplets using unstructured text and image data obtained from SLB product training manuals and help documentation. The data is split into semantically meaningful chunks based on the document title and section header information. These document chunks are provided as input to a multi-modal LLM and serve as ground truth contexts for the question answers pair generation. The context + QA (Question Answering) pairs thus generated are manually evaluated by subject matter experts at SLB and added to the pool of a few examples for generating additional examples.
Evaluation Metrics
Many traditional metrics exist for both retrieval (Hit Rate, Mean Reciprocal Rank) and natural language generation (BLEU, ROUGE, METEOR, BERTSCORE). While these metrics are good at measuring overlaps and providing objective scores, they lack fine-grained semantic understanding. Recent advancements utilize LLMs themselves to evaluate RAG system outputs, enabling more sophisticated and human-like assessments. RAGAS is a popular open-source framework that implements LLM-based evaluations. It defines the following key metrics to evaluate retrieval and generation components.
- Context Precision (Retrieval): Measures the relevance of the retrieved context to the user's question.
- Context Recall (Retrieval): Evaluates whether all necessary information for answering the question is present in the retrieved context.
- Answer Relevancy (Generation): Assesses the relevance of the generated answer to the user's question.
- Faithfulness (Generation): Determines whether the generated answer is grounded in the provided context and avoids hallucinations.
- Answer correctness (Generation): Measures the generated answer’s factuality and semantic similarity concerning the ground truth answer.
Evaluating RAG systems on such metrics makes them a lot more interpretable and steerable. When combined with our curated domain datasets, these metrics provide strong insights into the strengths and weaknesses of the system and inform on product evolution.
Conclusion
Addressing the AI challenges of the energy industry requires much more than just training LLMs on domain data. Making careful domain-aligned choices in development can make safer, more reliable LLM applications. This includes the introduction of safety features such as input guardrails and domain-focused evaluation and benchmarking to maximize potential and identify shortcomings. Guardrails on inputs are crucial for protecting LLMs from misuse. These safeguards, which need constant updates and thoughtful policy development, help prevent malicious or irrelevant use. Meanwhile, evaluation and benchmarking are essential for maximizing the potential of LLMs and RAG systems. By assessing their performance, we can identify weaknesses and build even more robust systems. We advocate for a nuanced and comprehensive approach that looks beyond traditional metrics and leverages existing frameworks like RAGAS while tailoring the evaluation process to specific domain needs. Our approach at SLB is designed to leverage both innovative technology and the extensive expertise of our domain experts to deliver pragmatic solutions that meet the industry's specific needs, ensuring safety, reliability, and the effective utilization of AI in the energy domain.