Tailoring Large Language Models for Specific Domains
The flow chart below presents a customization decision tree that we have developed to help with making these decisions based on your data and needs. The further sections talk about the different customization techniques in detail and at the end present a holistic approach to choosing the right technique for your use case.
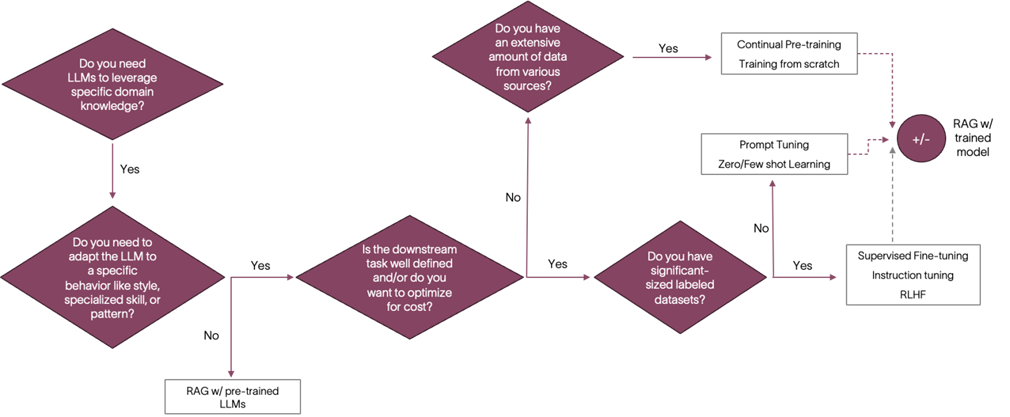
Fig 1. LLM customization Decision Tree
Prompt Engineering: Guiding with Context and Examples
Prompt engineering involves giving the LLM extra information in the input prompt to guide its responses toward a specific area. This involves experimenting with different formats, phrases, and symbols to find the best way to direct the LLM for a meaningful interaction. Prompt engineering is a flexible tool that works well with other LLM fine-tuning techniques. It can be used on its own or alongside methods like RAG and synthetic data generation to improve model performance during fine-tuning. At SLB, we use prompt engineering extensively in all our applications and use cases, highlighting its broad impact.
Popular Techniques:
- Instruction-based Prompts: Use clear, direct commands to guide the model (e.g., "Summarize this text").
- Few-shot Learning: Provide a few examples to show the model the desired input-output relationship.
- Chain-of-Thought Prompting: Encourage step-by-step reasoning to produce structured, logical responses.
- Domain Context: Include relevant domain-specific information directly in the prompt to ensure the model has a better understanding of the subject (e.g., "In the context of renewable energy, explain the benefits of solar power").
- Persona Prompts: Assign the model a specific role to influence its perspective (e.g., "You are a historian...").
Advantages:
- Data Efficiency: Requires a significantly smaller dataset compared to finetuning, often manageable for manual creation.
- Dynamic Updates: New information can be easily incorporated by modifying the prompt.
- Rapid Development: No model training is required, leading to faster development cycles.
- Controlled Outputs: Responses are more focused, grounded in the provided context, and follow a consistent format.
Challenges:
- Increased Inference Time: Longer prompts result in slower processing times.
- Higher Costs: Longer prompts consume more tokens, potentially increasing inference costs.
- Contextual Limitations: Providing comprehensive context, especially from multiple sources, can be difficult.
- Interface Changes: Prompting slightly alters the standard inference interface.
Retrieval Augmented Generation: Leveraging External Knowledge
While prompt engineering can be effective for adapting LLMs to certain tasks, it may not be the best solution for entire domains. This is because prompt engineering relies on embedding all relevant domain information within a single prompt, which may not be feasible when extensive knowledge is required. RAG offers a more comprehensive approach by connecting LLMs to external knowledge sources and domain-specific information. This allows LLMs to access relevant context and produce more accurate and domain-specific outputs. RAG leverages a knowledge-intensive strategy, utilizing an external database of domain-specific documents to provide context and enhance LLM responses.
Process:
- Database Creation: Domain-specific documents are encoded into embeddings using a language model, and these embeddings are stored in a vector database.
- Query Embedding: At inference time, the user's query is also converted into an embedding using the same language model.
- Document Retrieval: The query embedding is compared against the embeddings in the vector database to retrieve the most relevant documents.
- Response Generation: The top-ranked documents are provided to the LLM as context, enabling it to generate a more accurate and informative response.
Advantages:
- Automated Context: Eliminates the need to manually provide context within the prompt.
- Comprehensive Answers: Access to the entire corpus allows for more complete and informative responses.
- Dynamic Updates: The database can be easily updated with new information.
- Interpretability: Examining retrieved documents provides insights into the LLM's reasoning process.
- Modular Design: Allows for easy comparison and improvement by switching between different LLMs.
Challenges:
- Cost: RAG systems involve higher computational and storage costs compared to standalone LLMs.
- Latency: The multi-step retrieval process increases response time.
- Indexing Time: Building and updating the database can be time-consuming.
- Relevance Challenges: Retrieved documents may not always be relevant or accurate.
Building Domain-Specific Text Embeddings
Text embeddings are essential for enabling AI to understand and process language. They convert words and sentences into numerical vectors that capture semantic meaning, facilitating applications like content creation, translation, conversation, search, and information retrieval. While general-purpose text embeddings are widely available, they may not fully capture the nuances of specialized domains, limiting their effectiveness in specific applications. Domain-specific text embeddings address this by:
- Capturing Technical Language: Understanding domain-specific terms and concepts is key for accurate interpretation.
- Improving Decision-Making: More accurate representations of domain knowledge enhance decision processes.
- Enhancing Knowledge Management: Better organization, retrieval, and utilization of specialized knowledge is enabled.
- Boosting Operational Efficiency: Accurate understanding of domain-specific information streamlines operations.
These benefits highlight the importance of developing domain-specific text embeddings for various applications, including improving retrieval in RAG systems. We present a framework to effectively create domain-specific embeddings.
- Data Preparation: Ensure your training data is well-formatted (e.g., plain text, sentence pairs, labeled data) and of high quality.
- Choosing the Right Architecture: Select an appropriate architecture based on your data and task. Popular options include Sentence Transformers (SBERT), decoder models like LLM2Vec, or closed-source models from OpenAI and Google.
- Selecting the Appropriate Loss Function: The Multiple Negative Ranking Loss function is commonly used for fine-tuning. This function calculates the similarity between an anchor sentence and positive/negative samples within a batch.
- Evaluating and Benchmarking:
- Choose a relevant downstream task.
- Create a representative test dataset. This dataset should contain a list of data points that each has the following information: [question, answer, context, label] relevant to your task.
- Select appropriate metrics. Metrics can be absolute, or you can use an LLM as a judge for evaluation.
We applied this framework to create specialized geoscience embeddings. We generated comprehensive datasets containing question-answer pairs, labels, and relevant context. We also create appropriate test datasets to evaluate our models. We experimented with different training methods, including Supervised Fine-Tuning (SFT) and Parameter-Efficient Fine-Tuning (PEFT). We fine-tuned several open-source text embedding models, such as E5-mistral-7b-instruct and LLM2Vec-Mistral-7B-Instruct-v2-mntp-supervised, using our curated datasets. We evaluated retrieval performance on the test datasets using metrics like hit rate and Mean Reciprocal Rank (MRR). Additionally, we used the RAG with an LLM as a judge (Ragas) framework to conduct a comprehensive analysis of the models' performance. The preliminary results are promising, indicating that the framework provides valuable insights and improvements.
Fine-Tuning: Enhancing LLMs with Specialized Expertise
Fine-tuning is a more advanced technique for adapting LLMs to specific domains. The real power of fine-tuning lies in its ability to infuse LLMs with our domain knowledge, accelerating the development of new workflows, improving existing processes, and unlocking new opportunities for innovation across domains like reservoir characterization, well planning, and risk assessment. This approach requires a substantial amount of clean, task-specific data to optimize the model’s performance. By leveraging transfer learning, fine-tuning adapts a pre-trained LLM to a particular domain without starting from scratch, refining the model’s weights with domain-specific data to embed specialized knowledge.
Popular Techniques:
- LLM Alignment:
- Supervised Fine-Tuning (SFT): Train LLMs with curated datasets featuring industry-specific terminology and tasks.
- Reinforcement Learning with Human Feedback (RLHF): Enhance SFT by refining the model based on feedback from industry experts, aligning its responses with real-world decision-making.
- Advanced Techniques:
- Proximal Policy Optimization (PPO): Stabilizes learning by preventing drastic behavior changes.
- Direct Preference Optimization (DPO): Optimizes the model based on expert preferences (e.g.,prioritizing carbon reduction).
- Network Training:
- Full Fine-Tuning: Updates all model parameters, demanding significant resources.
- Parameter-Efficient Fine-Tuning (PEFT): Fine-tunes a subset of parameters, reducing computational demands and data needs.
- Prompt-Tuning (P-Tuning): Adjusts prompts for more relevant responses to specific queries.
- Low-Rank Adaptation (LoRA): Introduces low-rank matrices for task-specific adaptation with minimal changes.
- Synthetic Data Generation:
- Address Data Scarcity: Generate additional training data to compensate for limited domain-specific data.
- Methods:
- Self-Instruct Data Generation: Creates new training data for tasks like drilling, production, and reservoir engineering.
- Evolve Instruct Data Generation: Iteratively refines synthetic data based on model performance, improving both data and model.
Advantages:
- Retention of General Knowledge: Maintains the broad language skills from the original model.
- Data Efficiency: Requires less data than training from scratch.
- Speed: Faster than training a model from the beginning.
Challenges:
- Complexity and Overfitting: Fine-tuning can lead to overfitting and a loss of previously learned information.
- Dataset Size: A large dataset is still necessary for effective fine-tuning.
- Limited Adaptability: Updating the model with new information requires additional rounds of fine-tuning.
Energy Domain LLMs
Our current work leverages a combination of publicly available geoscience datasets and SLB product documents. Here's a breakdown of the methodologies employed:
- Continual Pre-training: We enhance pre-trained foundation models by continuing training with large quantities of unstructured data, updating model layers without adding new parameters. This has been applied to open-source LLMs using masked language modeling.
- Parameter-Efficient Fine-Tuning (PEFT): We utilize adapter modules during training to fine-tune models without altering their original parameters. PEFT methods like LoRA and QLoRA have been employed on Mistral Nemo and other open-source LLMs, adapting datasets accordingly.
- Instruction Fine-Tuning: SLB has developed an innovative dataset generation pipeline for creating large-scale, high-quality datasets specifically tailored for the energy sector. This pipeline leverages advanced synthetic data generation techniques and LLMs to produce diverse and comprehensive datasets. Instruction Fine-Tuning Pipeline Details:
- Techniques: Self-Instruct and Evolve Instruct iteratively refine prompts and responses, generating high-quality question-answer (QA) pairs relevant to the energy industry.
- Dataset Format: [Instruction, Question, Answer, Context]
- Fine-Tuning Techniques: PEFT (LoRA) and knowledge distillation.
- Model Evaluation:
- Energy Sector Benchmarks: Developed by SLB, these benchmarks are curated for the energy sector.
- Performance Metrics: BERT score, ROUGE score, and advanced frameworks like RAGAs using LLMs as judges.
Our instruction-tuned model shows a marked improvement over the base model across all metrics, showing that it's learning to understand the specific needs of the domain. The development of our new dataset creation process, which generates high-quality, tailored data for the energy sector, presents a valuable advantage for developing models that can address its unique challenges. This is an important step in our ongoing efforts to leverage AI's potential within the energy industry.
Choosing the right approach for your domain
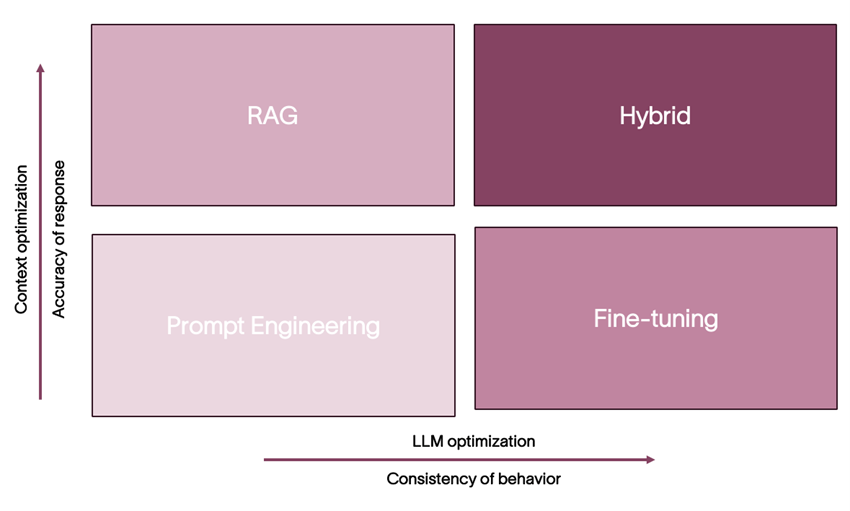
Fig 2. LLM Domain Adaptation Techniques.
While each method offers unique strengths, RAG generally proves more advantageous due to its:
- Flexibility: Adapts to data changes easily.
- Grounded Responses: Leverages external knowledge for more accurate and comprehensive answers.
- Faster Development Cycles: Avoids lengthy model training procedures.
- Interpretability: Provides insights into the reasoning behind the LLM's responses.
Prompt Engineering also offers significant benefits:
- Low Resource Requirements: No need for model retraining, making it more cost-effective.
- Task Adaptability: Enables quick adjustments to handle different tasks by changing prompts.
- Efficiency: Delivers relevant results with minimal configuration.
However, fine tuning may be preferable when we have:
- Sufficient Data: A large high-quality, static dataset is available for training.
- Domain-Specific Language: Finetuning can excel in handling specialized terminology.
A hybrid approach, combining finetuning and RAG, may prove optimal in scenarios with:
- Large, Static Knowledge Base: Finetuning on fundamental domain knowledge enhances overall performance.
- Dynamic Information Stream: RAG integrates new information and ensures up-to-date responses.
Conclusion
Domain adaptation of LLMs is a crucial step towards achieving truly versatile and reliable AI systems. These techniques empower these models to adapt to new and diverse data distributions, unlocking their potential for a wider range of applications. While challenges remain, particularly in terms of resource efficiency and robust generalization, ongoing research in areas like fine-tuning, few-shot learning, and data augmentation holds promising prospects. The future of LLMs hinges on their ability to seamlessly navigate the complexities of various domains, enabling them to empower industries, solve real-world problems, and ultimately, contribute to a more intelligent and adaptive world.
Domain adaptation is key to making LLMs truly useful in the E&P industry. SLB's long history of developing NLP solutions specifically for E&P puts us in a great position to lead this effort. We've combined our deep understanding of the industry with expertise in developing innovative NLP approaches, resulting in a powerful decision tree framework. This framework, built on years of experience, helps our LLMs go beyond simply adapting to E&P data and truly learn the intricacies of the domain. This strategic advantage gives SLB a leading role in the AI-driven revolution in E&P, allowing us to deliver transformative solutions that unlock new opportunities and accelerate progress within the industry.