Accelerating Wellbore Domain Interpretations Using Generative AI and Knowledge Graphs
Abstract
The petroleum industry relies heavily on accurate wellbore domain interpretation for effective resource management and extraction. Traditionally, this process involves numerous complex and time-consuming steps, such as data normalization, unit harmonization, and depth matching, often requiring extensive expertise. This paper presents an AI-powered solution designed to automate the creation of wellbore interpretation workflows, significantly enhancing efficiency and accuracy.
Our solution integrates generative AI, large language models (LLM), and graph-based methods to streamline the workflow creation process. The methodology involves three key steps: knowledge gathering from extensive documentation, automatic workflow generation through natural language interactions with a chatbot, and execution of quality-checked workflows. By leveraging a comprehensive knowledge base built from training manuals, API references, and historical interpretation data, our system can intelligently suggest optimal workflows in response to user queries.
Tests conducted using data from the Groningen field demonstrate the effectiveness of this approach. The time required to create a lithology computation workflow was reduced from the typical 15-30 minutes to just 10 seconds using our AI-powered workflow advisor. This represents a time reduction factor of up to 180 for junior petrophysicists. The knowledge graph employed in this process showed a 93% accuracy in building workflows, ensuring reliability and precision.
This innovative solution not only saves time but also minimizes errors, enabling non-experts to perform accurate data interpretation. The AI-powered workflow advisor represents a significant advancement in the automation of wellbore interpretation tasks, demonstrating the potential of machine learning to revolutionize the petroleum industry. By automating tedious and complex processes, our solution contributes to faster, more reliable wellbore analysis, ultimately improving decision-making and operational efficiency.
Introduction
Wellbore domain interpretation requires intricate steps to reach the final output, often consuming significant time and prone to errors, especially for less experienced geoscientists. This paper addresses these challenges by introducing an AI-powered solution utilizing Generative AI and Knowledge Graphs. The solution automates workflow creation by leveraging historical interpretations, logs, and documentation, dramatically reducing the process from minutes to seconds. This approach enhances efficiency, accuracy, and accessibility, enabling both experts and non-experts to perform reliable wellbore interpretations swiftly and effectively.
This study is composed of 3 main steps:
- Knowledge gathering: Building different knowledge bases from various sources of documentation including training manuals.
- Automatic workflow creation: Leveraging graph-based methods and large language models (LLM) to build a sequence of methods defining the optimal workflow.
- Workflow execution: Automatically build the workflow based on available Python APIs.
Knowledge gathering: Data exploration and description
To streamline the processes of data gathering and integration, we employed data interpreted using Techlog PTS (Petro-Technical Suite). Techlog, a commercial solution by SLB, is designed for interpreting wellbore data, including logs, core measurements, and wellbore images across various domains such as petrophysics, geomechanics, reservoirs, and drilling. A notable advantage of Techlog PTS is its connection to WDMS (Wellbore Data Management Services), which is part of SLB’s OSDU™ Data Platform initiative (Open Subsurface Data Universe). WDMS provides a commercial E&P data platform that can be deployed on the operator’s infrastructure or their chosen cloud.
Documentation ingestion pipeline:
At this stage, the purpose is to bring together all useful data types. The main input here was the Techlog documentation files, captured as xml files from the application installation folder. PDF Training manual and reports were also captured at this step. Other documents like old reports and trips & tricks files were stored as images. All files are stored within an internal data partition. Many users can upload files to the same data partition. Due to the important number of help files from Techlog documentation, a script was implemented to automatically trigger all files in one shot. Of course, the ingestion pipeline was running sequentially on top of each of these files.
All these documents contain knowledge about the workflows that users run using Techlog to compute specific variables. For example, according to Techlog help, we know that to perform a Lithology computation users need to provide at least four logs: Effective Porosity, Shale Volume, Flushed Zone Water Saturation, and Bulk Density. Also, a Shale Volume log could be computed from a gamma ray log using VSH method. This is exactly the type of knowledge we are targeting to capture in this part of the study. Below, Figure 2, is a representation of how this information is figured under Techlog help document.
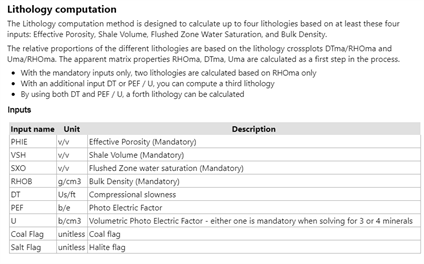
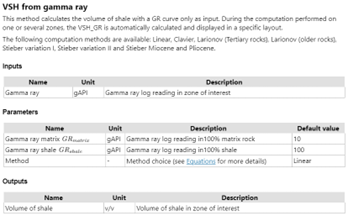
Figure 2: Techlog help for Lithology and VSH from gamma-ray computations
To reach this target, an ingestion pipeline is implemented in several steps to support the different file types. Below, we will focus on processing steps for images, non-searchable PDF and scanned documents. Figure 3 shows all the steps we went through before running the LLM to extract the workflows.
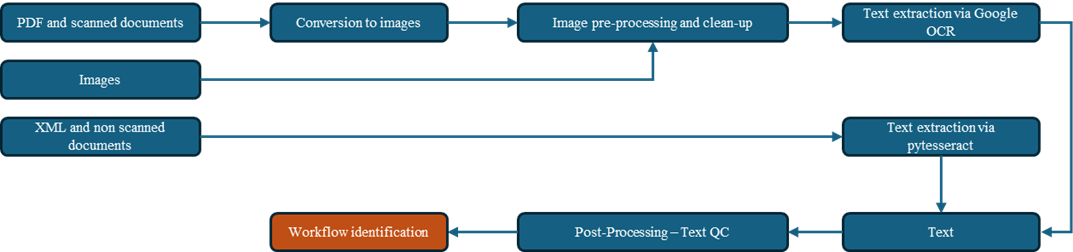
Figure 3: Documentation ingestion pipeline
Pre-Processing Step: Enhancing Image Quality for Optimal OCR
Pre-processing an image is essential to improve the accuracy and efficiency of Optical Character Recognition (OCR). Below are the different steps we performed to pre-process the images and clean them up:
- Convert to Grayscale: Converting the image to grayscale. This simplifies the image by focusing on luminance and ignoring color, making subsequent processing easier.
- Correct Image Skew: If the image is tilted, it can distort the text, making OCR less effective. Correcting the skew aligns the text horizontally.
- Remove Noise: Eliminating noise to enhance the clarity of text regions. This was achieved using median blurring and other filtering techniques.
- Binarize the Image: Converting the grayscale image to a binary image using thresholding. This step separates the text from the background.
- Perform Morphological Operations: Using morphological operations, such as dilation and erosion, to further clean up the image and emphasize the text.
- Remove Borders: Remove any borders or edges that could interfere with text recognition.
In the figure below, we show the effect of the image pre-processing steps.


Figure 4: Final result after running all pre-processing steps on top of an image of a public document. The original image is on the left and pre-processed output is on the right.
OCR Processing: Extracting text from images using OCR models
The image is now ready for OCR. The OCR processing stage is fundamental to the overall workflow of text extraction from images. By meticulously selecting and applying the appropriate OCR model, coupled with robust pre- and post-processing techniques, we can significantly enhance the accuracy and reliability of the extracted text. This ensures that the downstream applications, such as text analysis and data mining, are based on high-quality, machine-readable text. In this study, we used Google OCR. This service integrates a high-accuracy module that allows not only text extraction but also classifies and splits documents. This process is called Document-AI. It helped a lot on enhancing data extraction and achieving more profound insights from both unstructured and structured document information. Below is the result of running Google OCR to get the text from the pre-processed image shown in Figure 1.



Figure 5: Final result after running OCR process on top of the cleaned image in Figure 4. The original image is on the left and the extracted text is on the right.
This step involves using an OCR model to convert the pre-processed image to text, retaining the layout of the original well report page. For non-scanned documents, such as searchable PDFs, this step can be replaced with a text extraction library, with the goal of obtaining a text output. Tools like pytesseract [10] can convert to searchable PDFs, and libraries like pdftotext [15] can extract text while preserving layout.
Post-Processing: Ensuring the Quality and Usability of Extracted Text
In the workflow extraction process, post-processing plays a pivotal role in refining the raw text obtained through Optical Character Recognition (OCR). This section details the procedures involved in correcting the text layout, identifying and fixing errors, and ensuring proper storage of the extracted text. These steps are crucial for enhancing the accuracy and readability of the extracted data, thus making it suitable for subsequent analysis and applications.
Correct Text Layout
To align the extracted text's structure with the original document's format, ensuring readability and logical flow. Line Breaks and Spacing: OCR often introduces unnecessary line breaks, especially in documents with complex layouts or multi-column formats. These need to be adjusted to form coherent sentences. For paragraph and section separation, it's important to preserve the natural separation between paragraphs and sections to maintain the document’s logical flow. For documents containing tables, it is essential to retain the table structure. This involves aligning columns and rows correctly to ensure data cells correspond accurately to their headers. Regular Expressions (Regex) library was employed to detect and correct patterns such as misplaced line breaks or inconsistent spacing.
Check for Errors
To identify and correct errors introduced during the OCR process, thereby enhancing the text's accuracy and readability. For spelling and grammar check we utilized automated spell-checking algorithms to identify and correct typographical errors.
Example: Correcting "JURASSIC" mistakenly recognized as "TURASSIC". We had to ensure that the extracted text makes contextual sense, particularly for technical or domain-specific documents. For this purpose, we used a spell checker library named SymSpell. The post-processing phase is essential for converting raw OCR-extracted text into clean, accurate, and well-structured data. By systematically correcting text layout, identifying and rectifying errors, and ensuring proper storage, we enhance the reliability and usability of the extracted information. This meticulous approach ensures the data is suitable for various downstream applications, including analysis and decision-making.
Automatic workflow creation: Leveraging graph-based methods and large language models (LLM)
Now we have our text documents cleaned and ready for metadata extraction. Our methodology utilizes the LLaMA2 (Large Language Model Meta AI) to extract workflows from textual data. The approach involves several steps, including environment setup, prompt design, and iterative refinement to achieve accurate extraction of workflows. The focus is on designing effective prompts that guide the LLM to identify and structure workflows effectively.
Leveraging LLM based on documentation and common knowledge
Large Language Models (LLMs) have shown remarkable capabilities in understanding and generating human-like text. Many LLM techniques exist to accomplish this task. In this study, we leverage LLaMA2 to extract structured workflows from unstructured text data. Workflows are defined as sequences of steps composed of a list of methods linked with input and output variables.
Environment Setup
We utilized the LLaMA2 model, which is accessible through the Hugging Face Transformers library. The setup involves installing the necessary libraries and loading the pre-trained LLaMA2 model and tokenizer.
Prompt Design
Designing effective prompts is essential for extracting workflows accurately. The process involves iteratively crafting and refining prompts to guide the LLaMA2 model. The principles of clarity, specificity, context, and guidance are adhered to in prompt design.
We begin with basic prompts to understand how the model responds. For instance:

To improve accuracy, we enhance prompts by adding context and specifying the desired output format. For example:

Providing examples within the prompt helps the model understand the desired output structure. For instance:

Review and Refinement
The extracted workflows are reviewed for accuracy and completeness. Based on the initial results, the prompts and model parameters are refined iteratively to improve the extraction quality.
At this stage of the study, we figured out that even after providing more detailed and refined prompts the model remains unable to answer an important number of our queries. We had the opportunity to enhance the prompt design with more sophisticated examples and explore the use of other LLMs to compare extraction accuracy and efficiency. Additionally, integrating feedback loops to continuously improve the model’s performance based on wellbore interpretation history records could be beneficial. We decided to leverage Knowledge Graph combined with the power of the Cypher query language.
Leveraging graph-based methods using Cypher
Knowledge graphs provide an advanced mechanism for representing complex relationships between entities. By using Cypher, the graph query language for Neo4j, we can model and query these relationships. The Knowledge Graph is built with methods and input/output parameters as two distinct types of Nodes, and the API reference provides information of the relationship between them.
The API reference file, Figure 6, is a consolidated document provided by Techlog Workflow Manager tool and it defines each of the domain methods by its input, output, and other information that could be useful for our study.
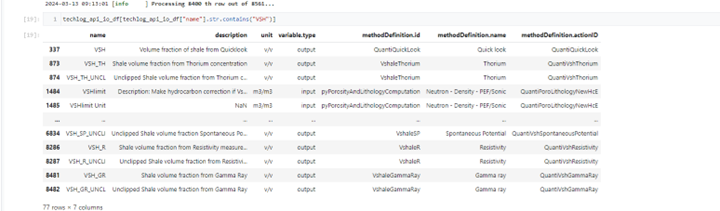
Figure 6: A partial capture on Techlog API reference file
What we call a parameter is either an input or output of a given method. In Figure 7, we are presenting all parameter nodes in purple and all method nodes in orange. The segments between nodes define if the parameter was used or produced by the method.
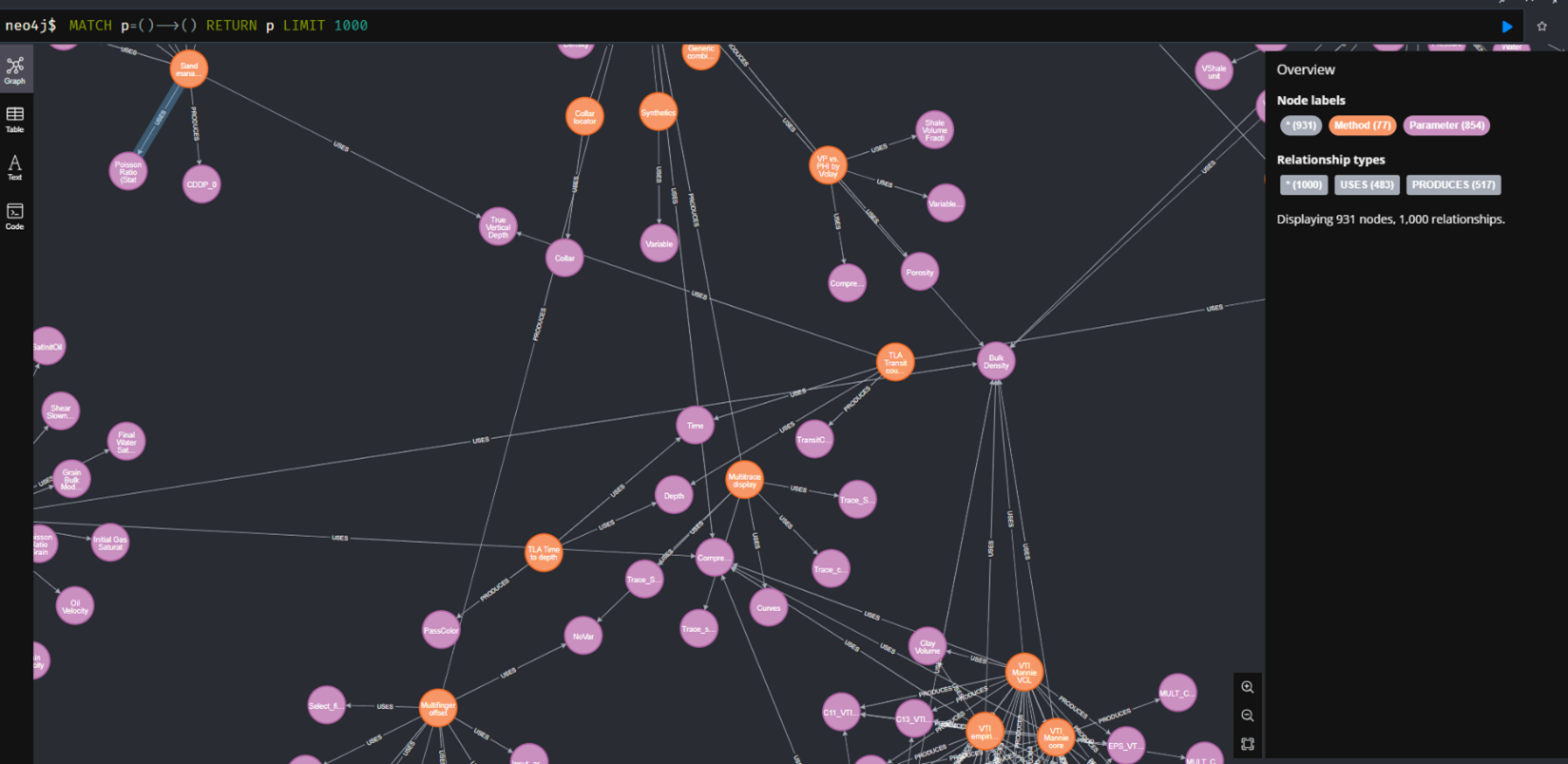
Figure 7: All Techlog methods mapped with Knowledge Graph
Once the graph is modelized, we further enhance the relationships with other metadata such as the mandatory nature of certain inputs and the connection strength derived from the LLM model produced in the previous section. At this stage, we are combining both techniques. The knowledge graph will provide us with all the possible paths to create a workflow. And, the LLM model will guide us toward the “best path” based on the common knowledge and Techlog documentation parsed previously using the LLaMA2 model. Hence, the graph efficiently represents the search for optimal workflows. For an optimized query, the computation time is in seconds.
First, we started by very simple queries as you can see below:

Then iteratively we come into more detailed and optimized queries that allowed us to reach fantastic results. Below is an example of an output message we got for the query above:

Discussion
The combination of LLaMA2 model and knowledge graphs using Cypher offers significant advantages for mapping method relationships and extracting workflows:
- Scalability: The graph model scales seamlessly with the addition of new methods and parameters.
- Flexibility: Cypher's expressive querying capabilities allow for detailed and complex workflow extractions.
- Efficiency: Enriched metadata enhances query performance and accuracy, ensuring efficient extraction of optimal workflows.
Now the service is ready to be integrated within Techlog and automate the workflow creation.
Workflow execution: Automatically build the workflow
Now we call this service directly from Techlog. The advantage of this step is that we are having the project context in Techlog. Meaning that we have the list of available logs. This is a very valuable input of the workflow creation tool. The second important advantage of integrating this tool within Techlog is that we are close to the interpretation history of all the logs. This contains the workflow steps achieved to compute the logs. We consider this input as one of the most valuable pieces of information to generate the workflow as it comes from real interpretation run by the user. We will consider this as a second input to evaluate the ‘best path’ within the Knowledge Graph. Now, the connections between parameters and methods are weighted by the LLM model and the interpretation history records.
Below is the complete workflow showing all possible use cases to build the final computation steps in Techlog context.
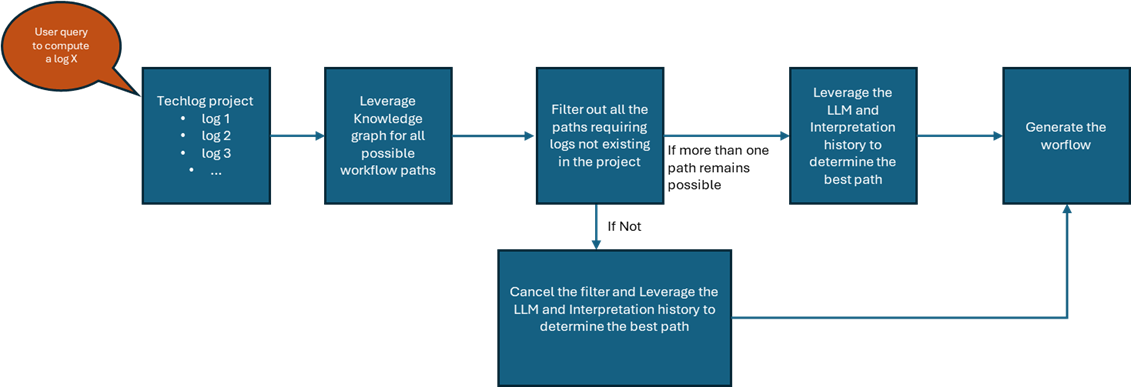
Figure 8: Presentation of possible ways to generate a workflow within Techlog
A Wellbot Techlog plugin was implemented consuming Python APIs to generate the workflow within the Application workflow interface (AWI) in Techlog. Also, a simple UI was implemented so that users could type in queries. Below is a representation of this workflow running is Techlog for a Lithology computation query using Groningen field data. It took us a few seconds to generate the final workflow for more than 70 wells in one query.
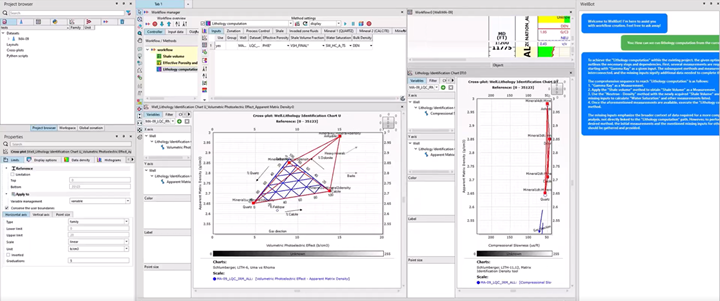
Figure 9: Final presentation of the workflow running in Techlog with the Wellbot and the generated workflow using AWI
Conclusion
Integrating generative AI and knowledge graphs to automate wellbore domain interpretations represents a significant advancement in the petroleum industry. Traditionally, wellbore interpretation has required extensive expertise and considerable time, often prone to errors. Our AI-powered solution streamlines this process, enhancing efficiency and accuracy.
Our approach involves three key steps: knowledge gathering from diverse sources, automatic workflow generation using large language models (LLMs) and knowledge graphs, and execution within the Techlog environment. By leveraging LLaMA2 and a comprehensive knowledge graph, our system extracts structured workflows from unstructured text, ensuring scalability, flexibility, and efficiency. Incorporating metadata and interpretation history allows for intelligent suggestions, reducing workflow creation time from 15-30 minutes to just 10 seconds, a reduction factor of up to 180.
Testing with Groningen field data demonstrated a 93% accuracy in workflow creation, underscoring the reliability of our approach. Integration within Techlog provides field context-aware workflow generation, enhancing user experience and enabling precise wellbore interpretations. This solution democratizes wellbore interpretation, making it accessible to non-experts and minimizing human error.
In conclusion, our AI-powered workflow advisor signifies a transformative leap in wellbore data analysis, driving faster, more reliable decision-making in the petroleum industry. This study highlights the immense potential of AI and knowledge graphs in revolutionizing traditional industrial processes and outcomes.
Acknowledgments
Support for the authors was provided by the SLB Montpellier Technology Center, particularly the DELFI team, which supplied the necessary infrastructure to run our algorithms and conduct tests. The authors also express gratitude to the Innovation Factory team in UAE - Abu Dhabi and USA - Houston for their interest in applying augmented learning to the wellbore domain and their willingness to evaluate our innovative solutions using field data.
References
- Brown, T. B., et al. "Language Models are Few-Shot Learners." Advances in Neural Information Processing Systems, 2020.
- Vaswani, A., et al. "Attention is All You Need." Advances in Neural Information Processing Systems, 2017.
- Devlin, J., et al. "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding." arXiv preprint arXiv:1810.04805, 2018.
- Hugging Face Transformers Library, available at: https://huggingface.co/transformers/
- Smith, R. "An Overview of the Tesseract OCR Engine." Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR), 2007.
- "ABBYY FineReader Engine." ABBYY, available at: https://www.abbyy.com/en-us/finereader/engine/
- Simonyan, K., and Zisserman, A. "Very Deep Convolutional Networks for Large-Scale Image Recognition." arXiv preprint arXiv:1409.1556, 2014.
- Hochreiter, S., and Schmidhuber, J. "Long Short-Term Memory." Neural Computation, 1997.
- "OpenCV: Open Source Computer Vision Library." Available at: https://opencv.org/
- Jain, A.K., and Kasturi, R. "Machine Vision." McGraw-Hill, 1995.
- Otsu, N. "A Threshold Selection Method from Gray-Level Histograms." IEEE Transactions on Systems, Man, and Cybernetics, 1979.
- Angles, R., & Gutierrez, C. (2008). "Survey of graph database models." ACM Computing Surveys (CSUR), 40(1), 1-39.
- Robinson, I., Webber, J., & Eifrem, E. (2015). "Graph Databases: New Opportunities for Connected Data." O'Reilly Media, Inc.
- Neo4j. (n.d.). "Cypher Query Language." Retrieved from https://neo4j.com/developer/cypher/
- Francois, M. (2014). "Knowledge Graphs: Opportunities and Challenges." arXiv preprint arXiv:1410.1757.
- SymSpell. [Available online: https://github.com/wolfgarbe/SymSpell]
- Google OCR and Document AI. [Available online: https://cloud.google.com/document-ai/docs/overview]